机器学习 | 变分自编码器 (VAE)
变分自编码器 (Variational Autoencoder, VAE):一种基于变分推断的深度生成模型,它通过将输入数据映射为潜空间中的连续概率分布,并从中采样解码来重构原始数据,从而学习到数据的潜在特征表示并能够生成全新的样本。
原始论文:Auto-Encoding Variational Bayes
1 自编码器
在学习变分自编码器 (VAE) 之前,不妨先回看自编码器 (AE) 的原理,这样我们能更好理解 VAE 到底解决了 AE 的哪些缺陷。
对于一个典型的 AE,它的结构如下:
- 输入层:输入高维的数据 $x$.
- 编码器 (Encoder):将高维的数据压缩为低维的特征 $h=f(x)$,通常是深度神经网络。
- 瓶颈层:通过编码器提取到的低维数据特征 $h$.
- 解码器 (Decoder):将低维的特征还原为高维的信号 $x'=g(h)$,通常是深度神经网络。
- 输出层:输出还原的高维数据 $x'$.
用图片表示如下:
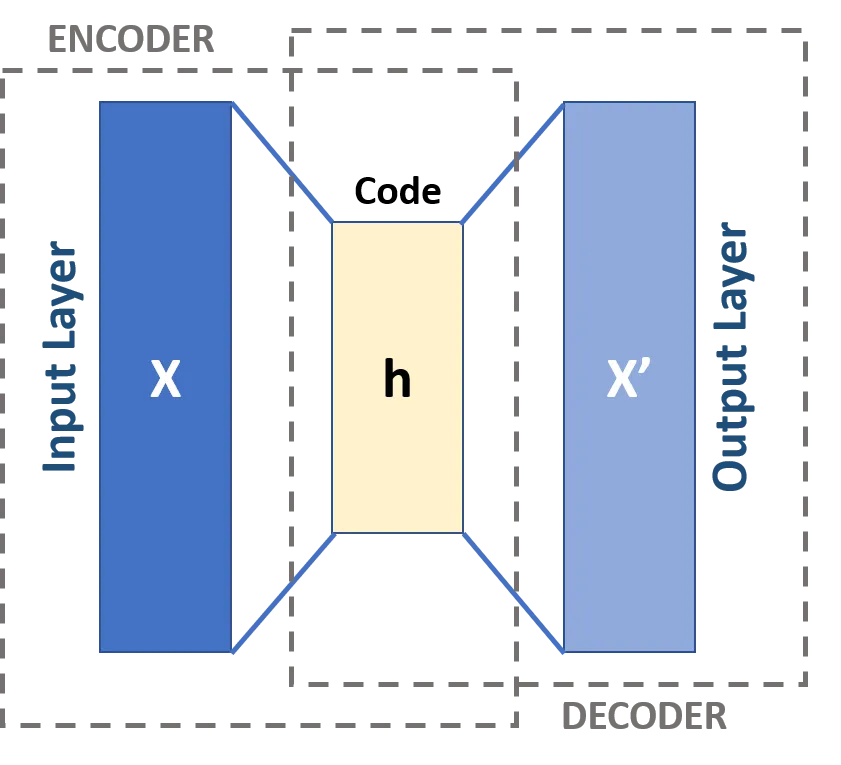
图片来源:https://en.wikipedia.org/wiki/File:Autoencoder_schema.png
协议:CC BY-SA 4.0
训练时,任务就是最小化重构损失 (Reconstruction Loss):
$$ \mathcal{L}=\Vert x-x'\Vert^2=\Vert x-g(f(x))\Vert^2 $$
但是 AE 存在一个核心问题,对于没有学习覆盖到的特征 $h$,使用解码器 $g(h)$ 大概率会得到无意义的输出(扭曲、模糊或完全噪声)。这个原因是 AE 的潜空间是稀疏的,点与点之间是离散的,往往没有规律可循。
这个缺陷就导致 AE 的泛化性能不佳,对于从未见过的新数据,编码器无法将其编码到合适的潜空间坐标,解码器拿到这个从未见过的坐标,通常也无法重构为原始数据。
| 自编码器 AE | 变分自编码器 VAE |
|---|---|
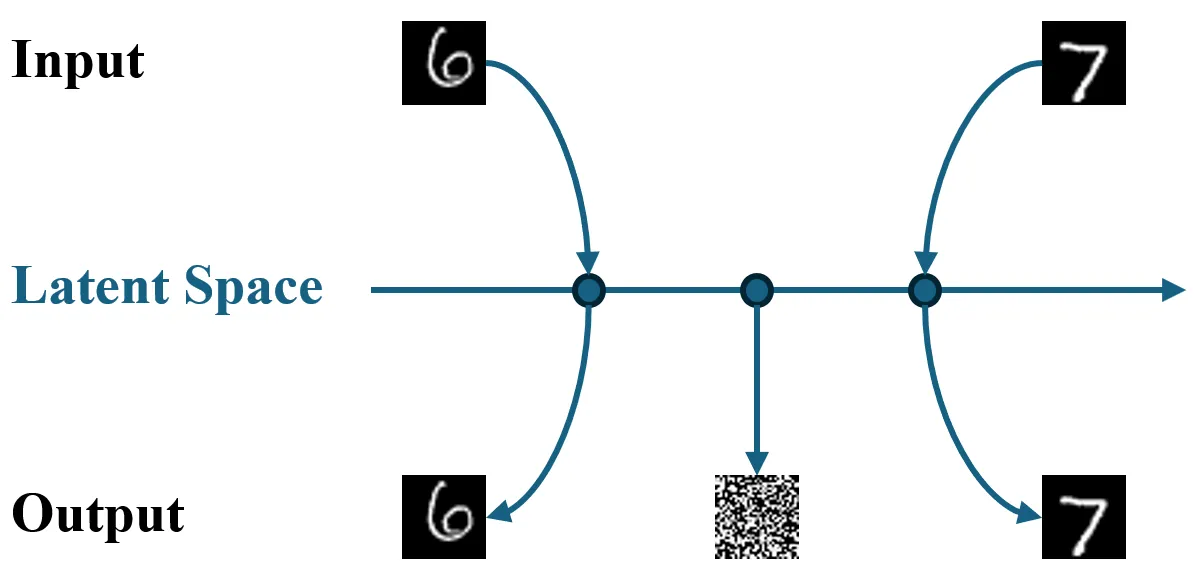 | 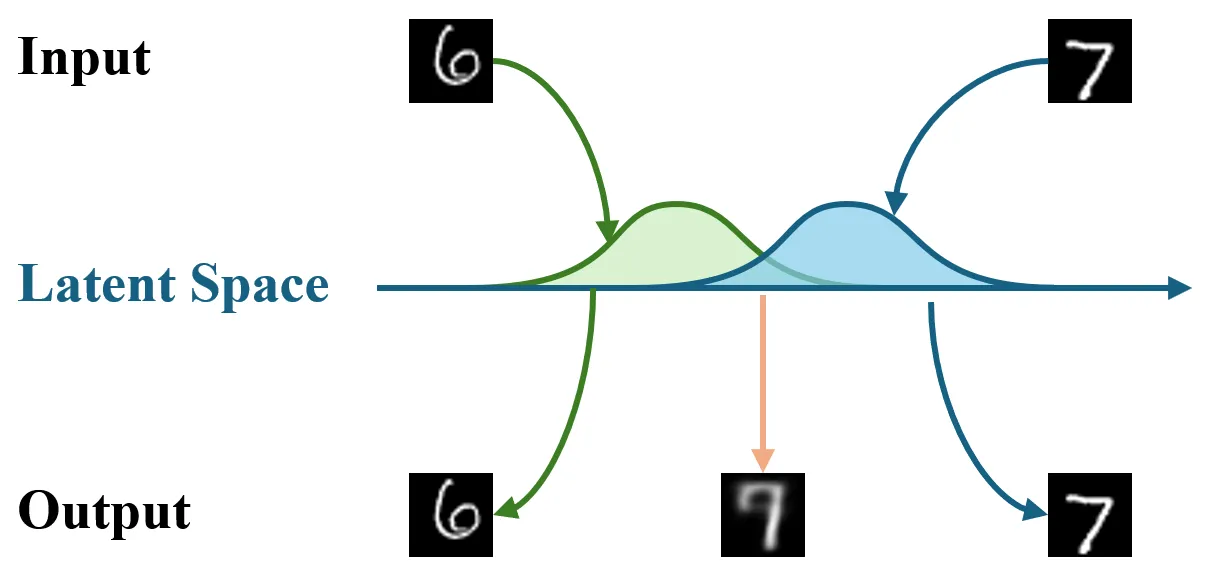 |
VAE 便解决了这个问题,VAE 的编码器并非将数据编码为固定的点,而是编码为一个连续的分布(通常为正态分布)。通过这种方式,VAE 能够让不同类别的分布产生合理的重叠,让潜空间的有效编码区域更稠密,同时实现了平滑连续的潜空间。
在 VAE 潜空间中相邻的两个点,解码出的图像是相似的,同时它的潜空间中几乎没有“真空地带”,即使随机采样一个训练中从未见过的点,解码器大概率也能根据周围“邻居”的特征,推测并生成一个合理的、具有语义的新样本。

图片来源:Auto-Encoding Variational Bayes
2 变分自编码器
2.1 核心问题
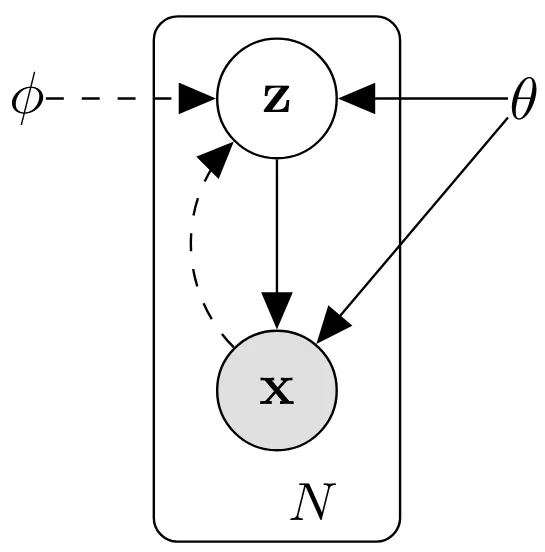
假设有一组独立同分布的真实数据 $x$,这些数据是由某种不可见的隐变量 $z$ 生成的,那么整个数据的生成过程可以描述为:
- 从某个先验分布 $p_\theta(z)$ 中采样出隐变量 $z$.
- 根据条件分布 $p_\theta(x|z)$(VAE 的解码器),由隐变量 $z$ 生成出观测数据 $x$.
我们的根本目标是最大化观测数据的边缘似然,即让我们的模型生成真实数据的概率最大化:
$$ p_\theta(x) = \int p_\theta(x|z)p_\theta(z)dz $$
但是由于隐变量 $z$ 的空间极其庞大,且在深度学习中 $p_\theta(x|z)$ 通常是由高度非线性的神经网络(解码器)参数化的,这个积分是极其难解的,因此我们无法通过这种方式计算得到 $p_\theta(x)$,同时真实的后验分布 $p_\theta(z|x) = \frac{p_\theta(x|z)p_\theta(z)}{p_\theta(x)}$ 也变得无法计算了。
贝叶斯公式名词补充:
$$ \overbrace{P(A|B)}^{\text{后验概率 (Posterior)}} = \frac{\overbrace{P(B|A)}^{\text{似然 (Likelihood)}} \cdot \overbrace{P(A)}^{\text{先验概率 (Prior)}}}{\underbrace{P(B)}_{\text{边缘似然 / 证据 (Evidence)}}} $$
2.2 变分推断与证据下界
为了解决这个问题,作者使用了变分推断的思想,不去计算真实的后验分布,而是通过神经网络参数化的近似分布 $q_\phi(z|x)$(VAE 的编码器)去拟合真实的后验分布。接下来,我们的任务就是为编码器 $q_\phi(z|x)$ 和解码器 $p_\theta(x|z)$ 找到最优的参数 $\theta$ 和 $\phi$.
根本目标仍然是最大化观测数据的边缘似然,不过这次用对数似然,在积分内引入 $q_\phi(z|x)$ 项:
$$ \log p_\theta(x) = \log \int p_\theta(x|z)p_\theta(z) dz = \log \int p_\theta(x|z)p_\theta(z) \frac{q_\phi(z|x)}{q_\phi(z|x)} dz $$
改写成期望的形式:
$$ \log p_\theta(x) = \log \mathbb{E}_{q_\phi(z|x)} \left[ \frac{p_\theta(x|z)p_\theta(z)}{q_\phi(z|x)} \right] $$
这一步用到的公式:
$$ \mathbb{E}_{g(x)} = \int g(x) f(x) dx $$
根据 Jensen 不等式(凹函数的期望小于等于期望的凹函数),由于 $\log$ 是凹函数,那么就可以得到:
$$ \log p_\theta(x) = \log \mathbb{E}_{q_\phi(z|x)} \left[ \frac{p_\theta(x|z)p_\theta(z)}{q_\phi(z|x)} \right] \geq \mathbb{E}_{q_\phi(z|x)} \left[ \log \frac{p_\theta(x|z)p_\theta(z)}{q_\phi(z|x)} \right]=\mathrm{ELBO} $$
不等号右边的部分被称为证据下界(Evidence Lower Bound, ELBO),它是目标函数 $\log p_\theta(x)$ 的下界。既然我们很难直接去计算 $\log p_\theta(x)$ 让它最大,那么我们就可以通过最大化它的下界,通过间接手段来使其趋向最大。
2.3 损失函数
根据上面的推导,VAE 的损失函数便是负的 ELBO,我们进一步展开它来探究损失函数的构成:
$$ \begin{align} \mathcal{L}&=-\mathrm{ELBO}=-\mathbb{E}_{q_\phi(z|x)} \left[ \log \frac{p_\theta(x|z)p_\theta(z)}{q_\phi(z|x)} \right]\\ &=-\mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)]+\mathbb{E}_{q_\phi(z|x)} \left[ \log \frac{q_\phi(z|x)}{p_\theta(z)} \right]\\ &=-\mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)]+D_{\mathrm{KL}}(q_\phi(z|x) \parallel p_\theta(z)) \end{align} $$
这一步用到的公式:
$$ D_{\mathrm{KL}}(p \parallel q) = \mathbb{E}_{p(x)} \left[ \log \frac{p(x)}{q(x)} \right] $$
那么,我们最小化损失 $\mathcal{L}$ 干的事情便是:
- 重构损失:最大化期望 $\mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)]$ 要求解码器 $p_\theta(x|z)$ 能够将编码器 $q_\phi(z|x)$ 编码的潜空间特征 $z$ 还原为原始输入 $x$.
- 正则化项:最小化 $D_{\mathrm{KL}}(q_\phi(z|x) \parallel p_\theta(z))$ 要求编码器输出的分布尽可能接近先验分布 $p_\theta(z)$(通常设定为 $\mathcal{N}(\boldsymbol{0},\boldsymbol{\mathrm{I}})$).
正则化项非常重要,假如只考虑重构损失,那么在训练过程中模型很可能会学到将输入编码为极细的尖峰从而获得极高的重构精度,这就直接使 VAE 退化为了 AE. 该正则化项,驱使模型编码时让平均的编码分布靠近设定的 $\mathcal{N}(\boldsymbol{0},\boldsymbol{\mathrm{I}})$,获得一个平滑连续的潜空间。
2.4 重参数化
要使用上述的方式进行梯度下降优化模型参数 $\theta$ 和 $\phi$,需要对 $q_\phi(z|x)$ 进行采样获得 $z$,而采样这个操作是不可微的,无法进行反向传播更新参数。
重参数化技巧是非常常见的解决该问题的方式(上一篇文章 DDPM 便用到了),简单来说就是隔离了计算过程中的随机部分和确定部分,将随机部分隔离在梯度传播之外,确保梯度只流过确定部分。
假设近似后验分布 $q_\phi(z|x)$ 是一个正态分布 $\mathcal{N}(\mu, \sigma^2 \boldsymbol{\mathrm{I}})$,基于重参数化技巧,编码器神经网络输出的不再是隐变量 $z$ 本身,而是这个分布的均值 $\mu$ 和方差 $\sigma^2$,获得均值和方差后,再通过以下方式得到 $z$:
$$ z = \mu + \sigma \odot \epsilon $$
$\odot$ 为哈达玛积。
这样,$z$ 的梯度就能成功流向 $\mu$ 和 $\sigma$,从而更新权重 $\phi$.
本文采用 CC BY-SA 4.0 许可,本文 Markdown 源码:Haotian-BiJi