杂项 | 并行计算集合通信
集合通信 (Collective Communications):分布式系统或并行计算中,用于在并发执行单元(GPU)间进行数据传输与同步的操作。
本文图片来源 The Ultra-Scale Playbook: Training LLMs on GPU Clusters,使用 Apache-2.0 协议,兼容 CC BY-SA 4.0 协议。
1 概念
1.1 广播 Broadcast & 散播 Scatter
- 广播是一个 $1\to N$ 的操作,特征是将来源为 $1$ 的数据完整复制到 $N$.
- 散播是一个 $1\to N$ 的操作,特征是将来源为 $1$ 的数据分片复制到 $N$.
示意图如下:
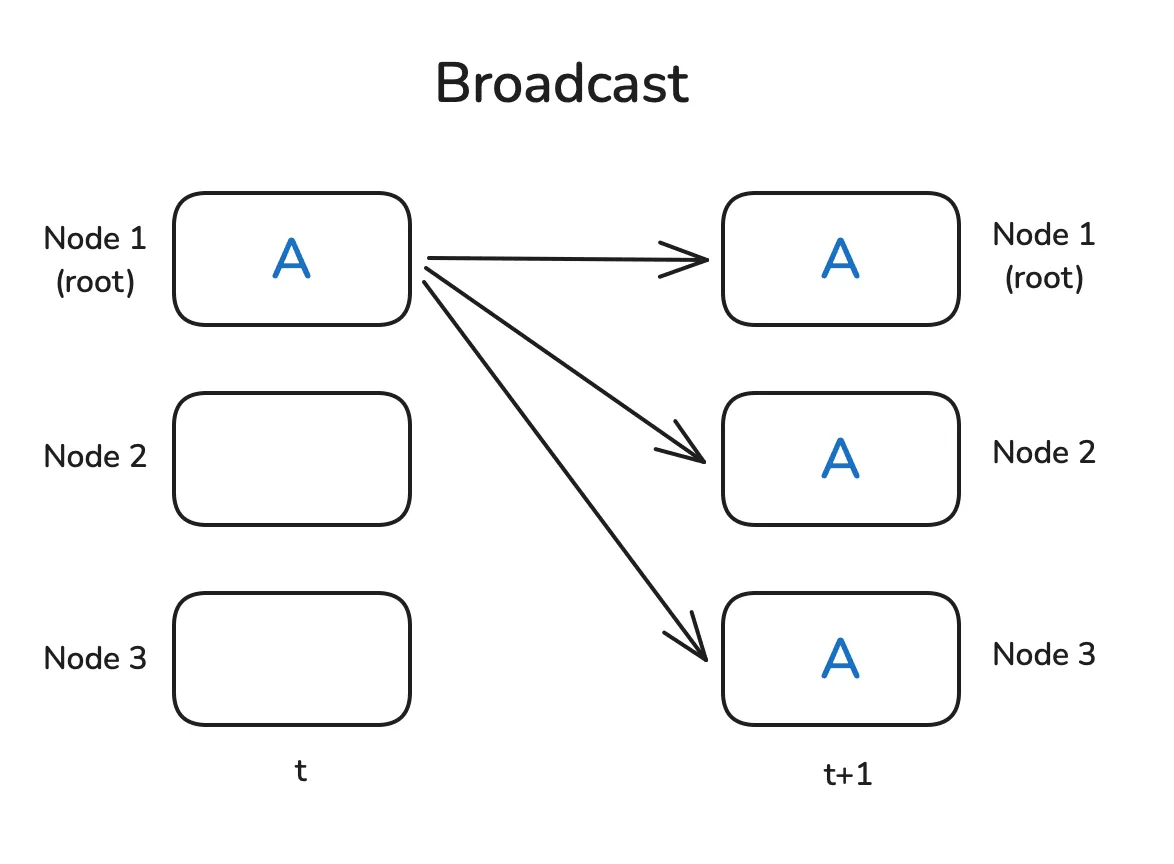 | 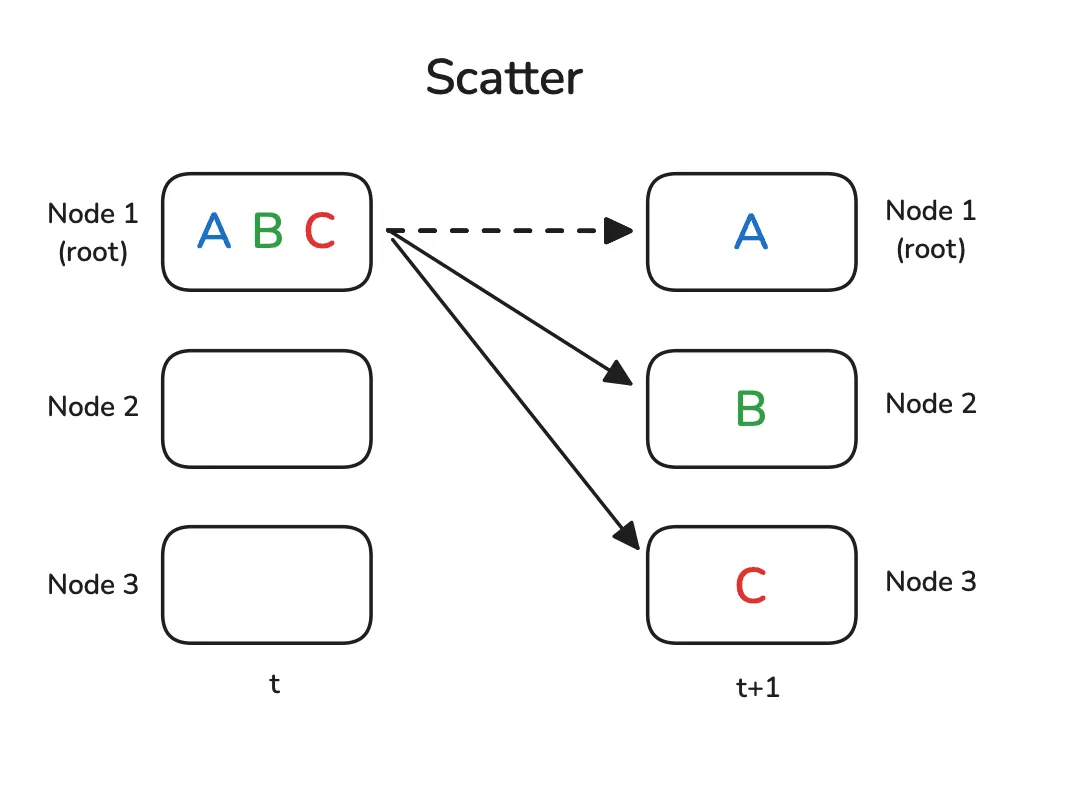 |
|---|
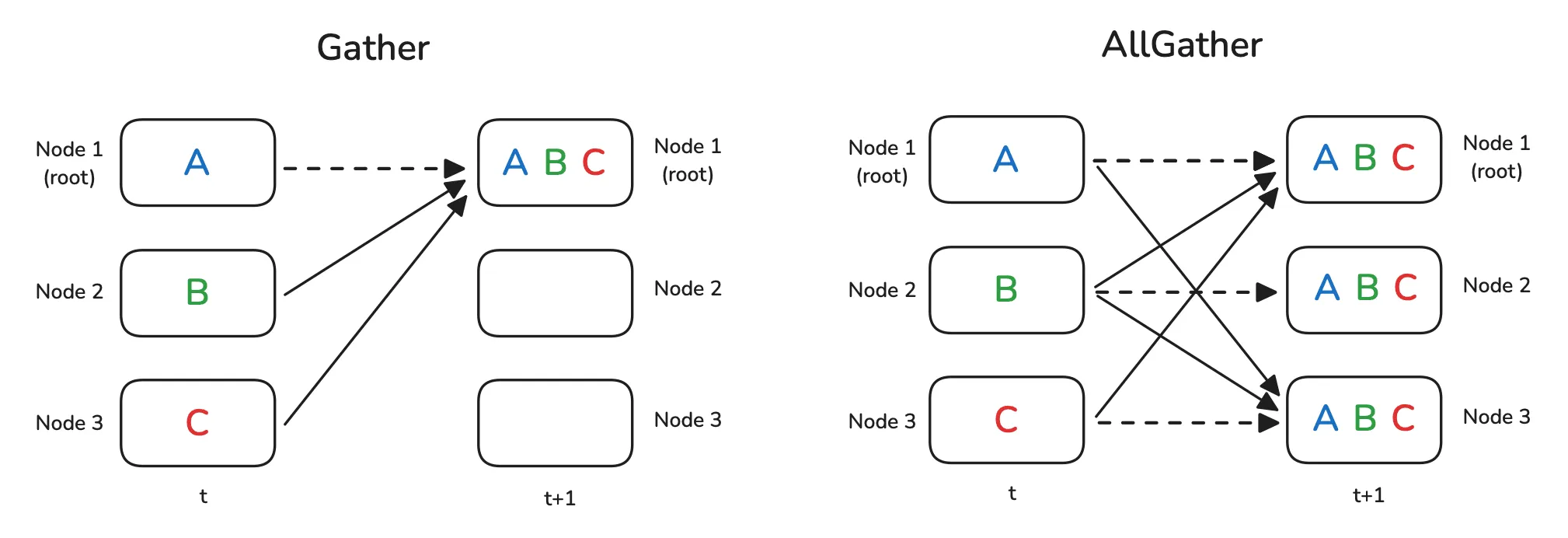
1.3 收集 Gather & 全收集 All-Gather
- 收集是一个 $N\to 1$ 的操作,特征是将来源为 $N$ 的数据复制整合起来,储存到 $1$ 中。
- 全收集是一个 $N\to N$ 的操作,特征是将来源为 $N$ 的数据复制整合起来,复制储存到 $N$ 中。
示意图如下:
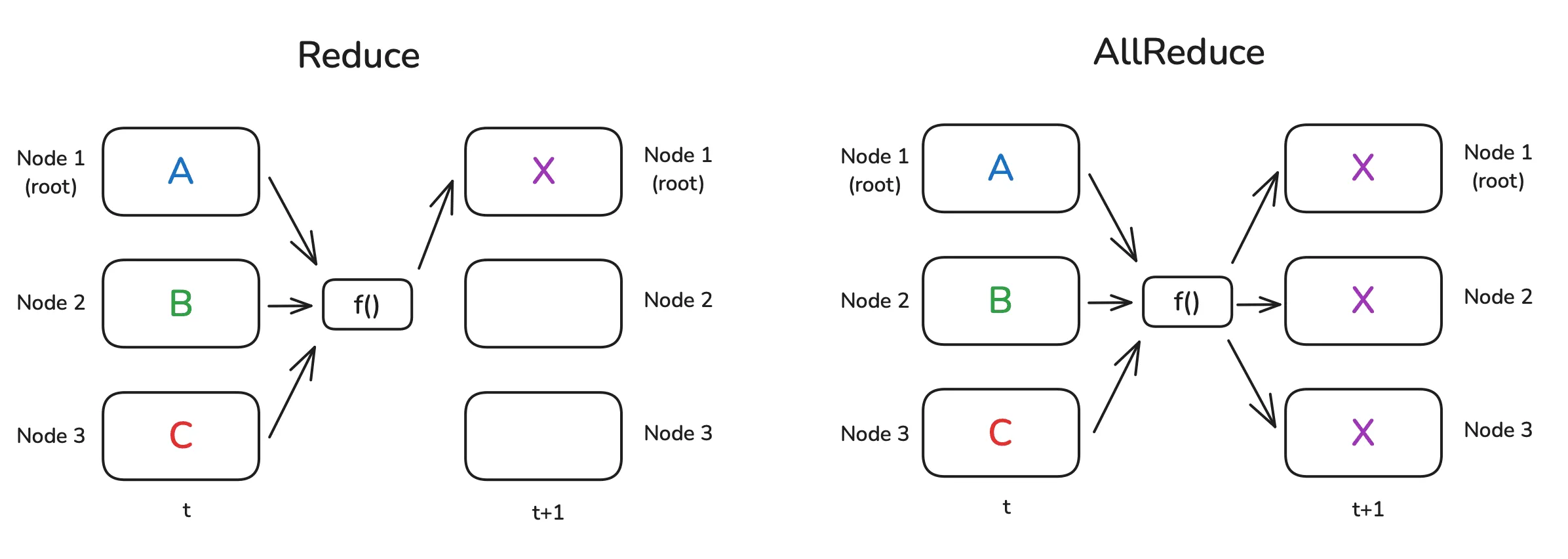
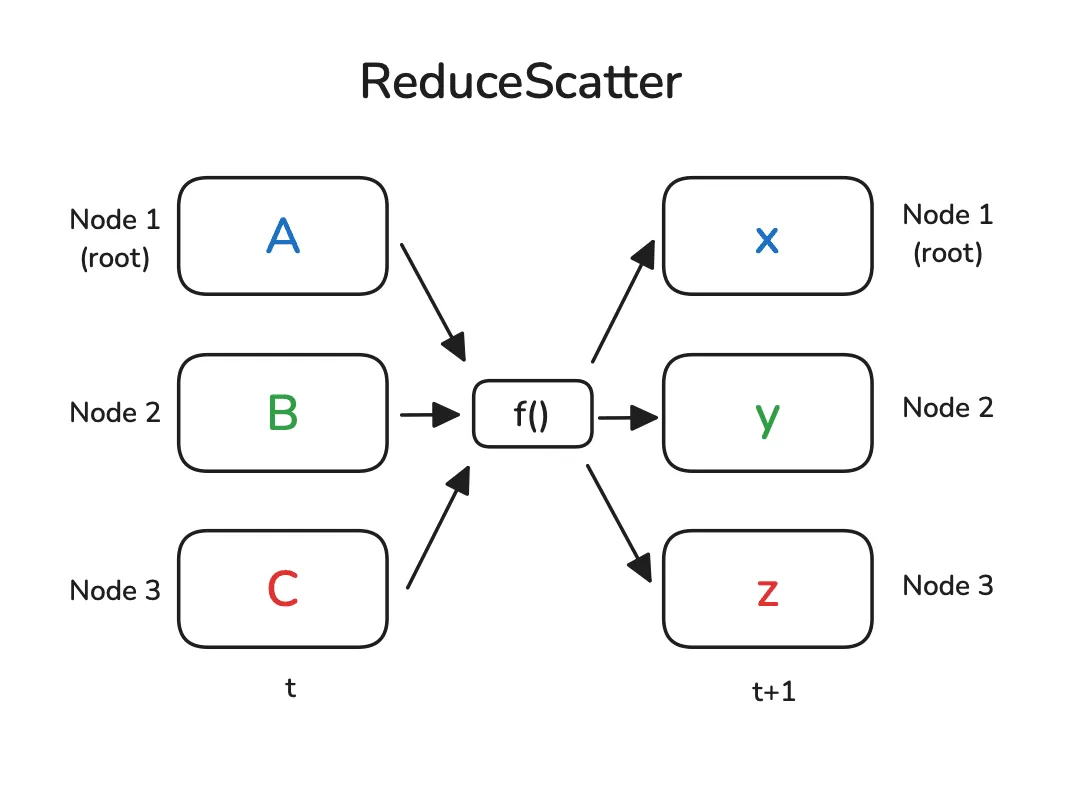
1.4 归约 Reduce & 全规约 All-Reduce & 规约散播 Reduce-Scatter
- 规约是一个 $N\to 1$ 的操作,特征是基于来源为 $N$ 的数据计算得到结果,将结果单独储存到 $1$ 中。
- 全规约是一个 $N\to N$ 的操作,特征是基于来源为 $N$ 的数据计算得到结果,将结果复制储存到 $N$ 中(在计算结果上等价于规约散播+全收集)
- 规约散播是一个 $N\to N$ 的操作,特征是基于来源为 $N$ 的数据计算得到结果,将结果分片储存到 $N$ 中。
需要注意的是,以上三种归约操作都不存在真正的收集操作将分片数据收集为完整数据(尽管下图看起来长得很像先收集再计算),也就是说归约操作只能用于满足交换律、结合律的算法(例如求集合最大值),对于不满足的算法(例如求集合第 $k$ 大值)是没法直接用规约完成的。
示意图如下:
2 开销
集合通信并不是一个固定算法,每种操作都有很多优化方式,甚至每种硬件的优化都不同,因此下文对开销的估计是定性的,均使用 Ring 算法。
| 操作 | 每节点通信量 | 总网络流量 |
|---|---|---|
| 广播 (Broadcast) | $\frac{n-1}{n} \Psi \approx \Psi$ | $(n-1) \Psi$ |
| 散播 (Scatter) | $\frac{n-1}{n} \Psi \approx \Psi$ | $\frac{n-1}{n} \Psi \approx \Psi$ |
| 收集 (Gather) | $\frac{n-1}{n} \Psi \approx \Psi$ | $\frac{n-1}{n} \Psi \approx \Psi$ |
| 全收集 (All-Gather) | $\frac{n-1}{n} \Psi \approx \Psi$ | $(n-1) \Psi$ |
| 规约 (Reduce) | $\frac{n-1}{n} \Psi \approx \Psi$ | $\frac{n-1}{n} \Psi \approx \Psi$ |
| 全规约 (All-Reduce) | $2\frac{n-1}{n} \Psi \approx 2\Psi$ | $2(n-1) \Psi$ |
| 规约散播 (Reduce-Scatter) | $\frac{n-1}{n} \Psi \approx \Psi$ | $(n-1) \Psi$ |
在计算分布式系统的通信耗时时,通常参考的是“单节点通信量”,因此可以简单记为:除了全规约操作两倍耗时外,其他操作均为一倍耗时。
为什么全规约操作是两倍耗时?
在高性能计算中,全规约通常通过规约散播和全收集两个步骤完成,因此它的操作耗时是两倍。
第一步:规约散播 第二步:全收集 P.s. 大模型训练中全规约是最昂贵的通信操作。
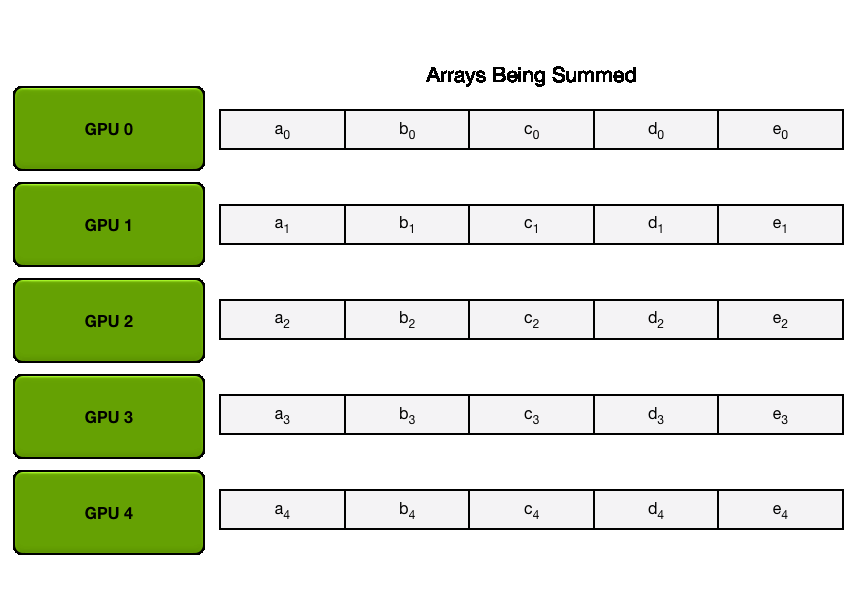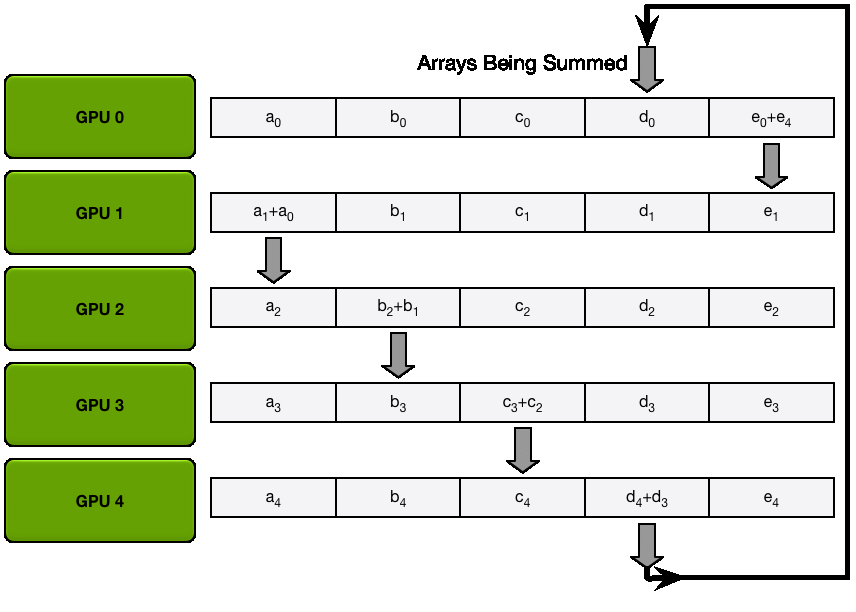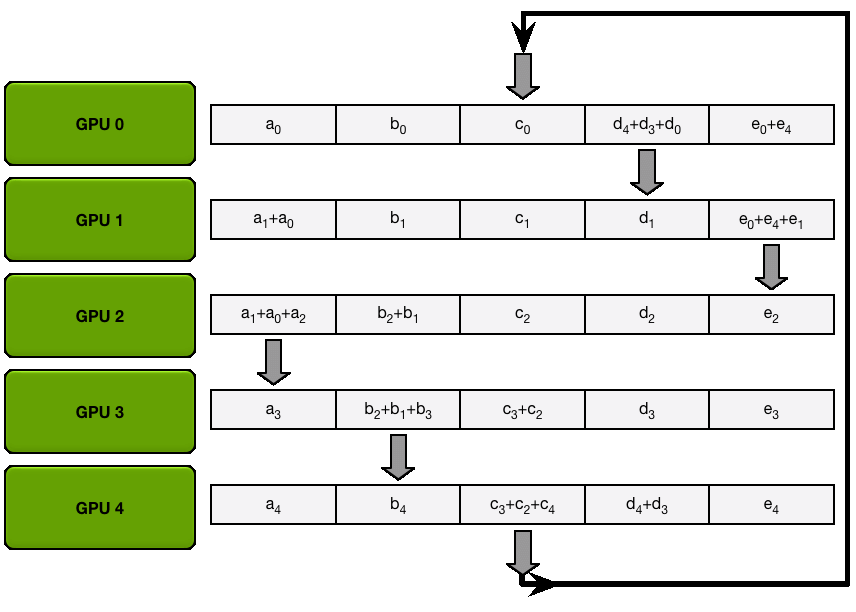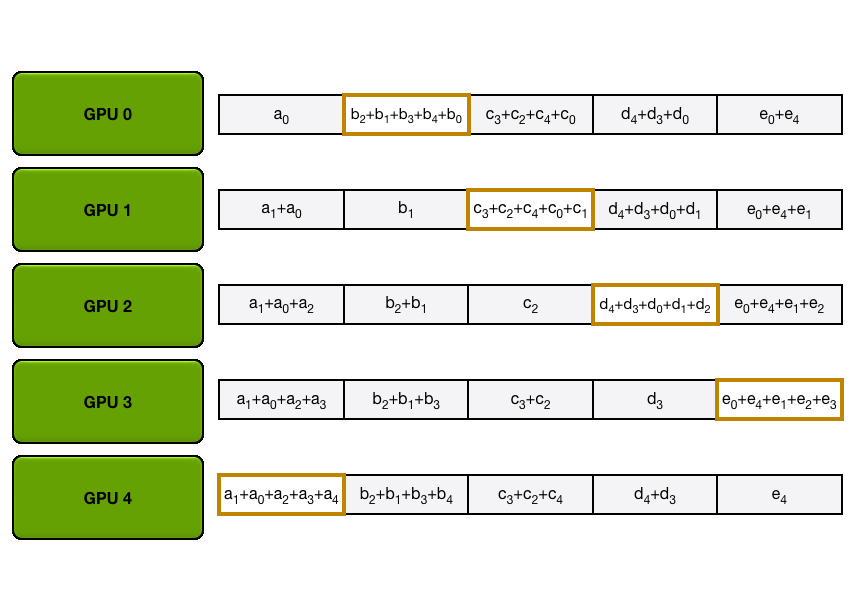
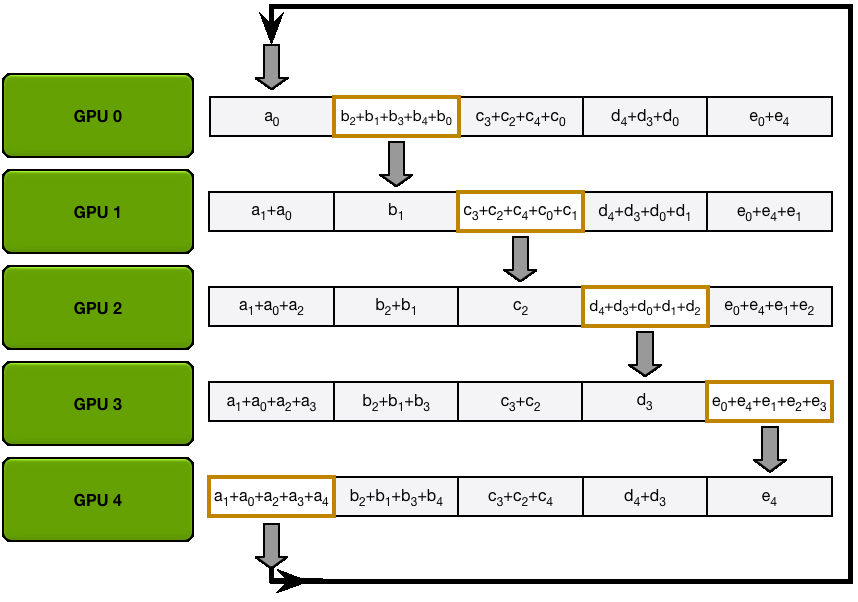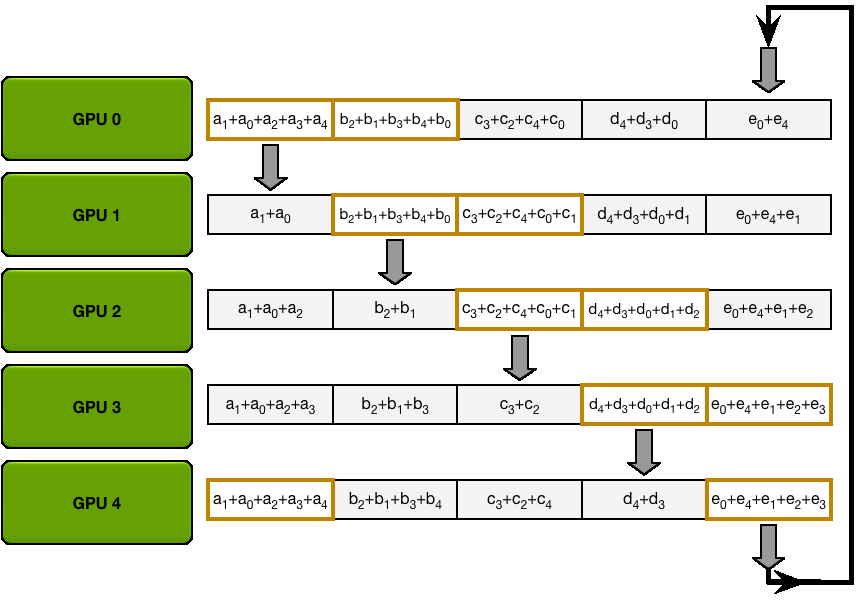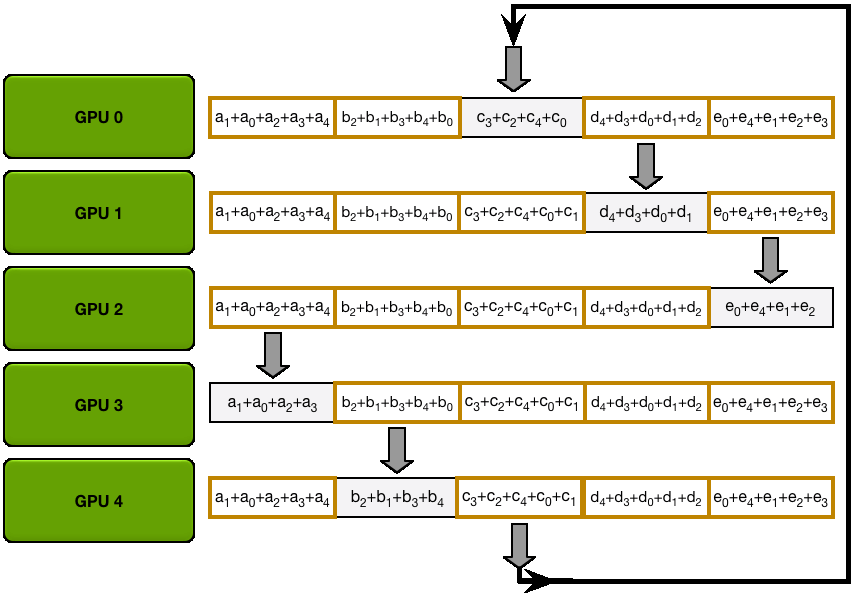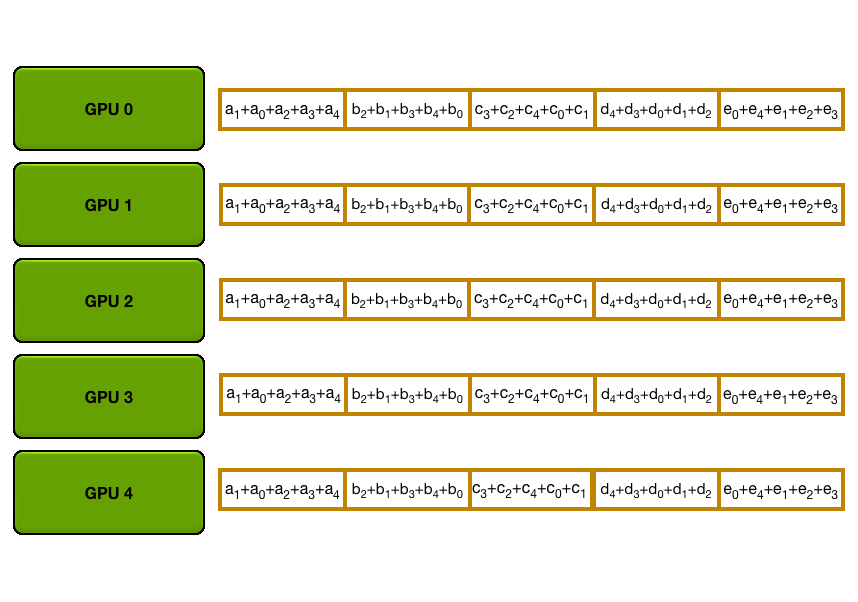
3 总结
| 中文名 | 英文名 | 数据流向 | 特征描述 | 单节点通信量 |
|---|---|---|---|---|
| 广播 | Broadcast | $1 \to N$ | 一份数据,全员拷贝 | $\approx \Psi$ |
| 散播 | Scatter | $1 \to N$ | 数据切片,分发全员 | $\approx \Psi$ |
| 收集 | Gather | $N \to 1$ | 收集碎片,聚于一点 | $\approx \Psi$ |
| 全收集 | All-Gather | $N \to N$ | 每个人都收集齐所有碎片 | $\approx \Psi$ |
| 规约 | Reduce | $N \to 1$ | 聚合计算,存于一点 | $\approx \Psi$ |
| 规约散播 | Reduce-Scatter | $N \to N$ | 聚合计算,但每人只拿一部分结果 | $\approx \Psi$ |
| 全规约 | All-Reduce | $N \to N$ | 聚合计算,且每人都拿到完整结果 | $\approx 2\Psi$ |
本文采用 CC BY-SA 4.0 许可,本文 Markdown 源码:Haotian-BiJi