机器学习 | LLM 并行方法(二)
本部分文章将涉及以下 LLM 并行方法:
- 上下文并行 (Context Parallelism, CP):旨在突破超长序列带来的注意力计算与显存平方级增长瓶颈。
- 流水线并行 (Pipeline Parallelism, PP):拥有极小的跨机通信开销,是突破单节点显存上限、实现多机大模型训练的核心基石。
- 专家并行 (Expert Parallelism, EP):专为混合专家模型 (MoE) 量身定制,实现多专家的负载与算力均衡。
本文图片来源 The Ultra-Scale Playbook: Training LLMs on GPU Clusters,使用 Apache-2.0 协议,兼容 CC BY-SA 4.0 协议。
本文需要前置知识并行计算集合通信,建议先确保了解七种集合通信方式再阅读本文。
1 上下文并行 Context Parallelism
1.1 概念
在上一部分的文章中介绍了数据并行 (Data Parallelism) 和张量并行 (Tensor Parallelism),它们都可以从不同层面上加速模型训练、降低显存开销。但随着模型的上下文长度越来越长,从 4K 一直增长到 128K,伴随着的就是平方增长的自注意力计算和激活值储存。平方增长的速度是非常恐怖的,数据并行和张量并行完全是没法应付的,因此上下文并行 (Context Parallelism) 应运而生。
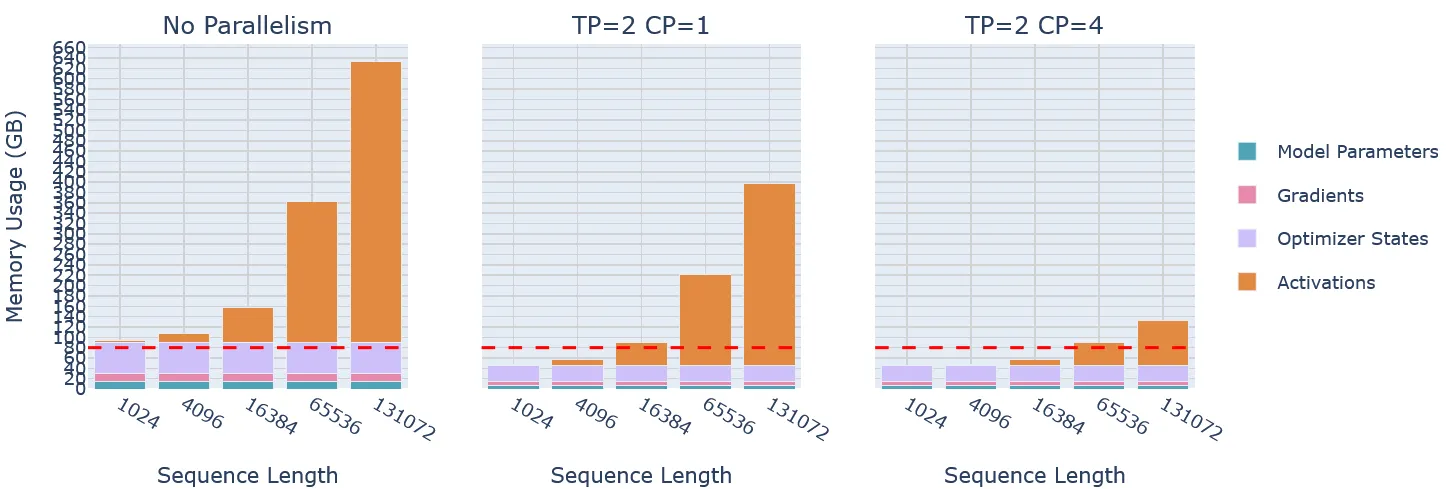
上下文并行针对的就是 LLM 的自注意力过程,它将模型的自注意力计算以及注意力激活值的储存分担到多个 GPU 上,降低单卡显存开销,让超长序列模型的训练成为了可能。
1.2 方法
回忆一下 LLM 自注意力的计算过程,首先是 $Q,K,V$ 的计算,就是对应的权重矩阵 $W_Q,W_K,W_V$ 与隐藏状态向量 $h$ 相乘:
$$ \begin{align} Q_i&=W_Qh_i\\ K_i&=W_Kh_i\\ V_i&=W_Vh_i\\ \end{align} $$
然后就是经典的注意力矩阵计算部分了:
$$ \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
为了直观,把上面这个公式展开来写成矩阵形式如下:
$$ \begin{bmatrix} \text{Softmax}(Q_1\cdot K_1) \cdot V_1 & 0 & \cdots & 0\\ \text{Softmax}(Q_2\cdot K_1) \cdot V_1 & \text{Softmax}(Q_2\cdot K_2) \cdot V_2 & \cdots & 0\\ \vdots & \vdots & \ddots & \vdots\\ \text{Softmax}(Q_n\cdot K_1) \cdot V_1 & \text{Softmax}(Q_n\cdot K_2) \cdot V_2 & \dots & \text{Softmax}(Q_n\cdot K_n) \cdot V_n \end{bmatrix} $$
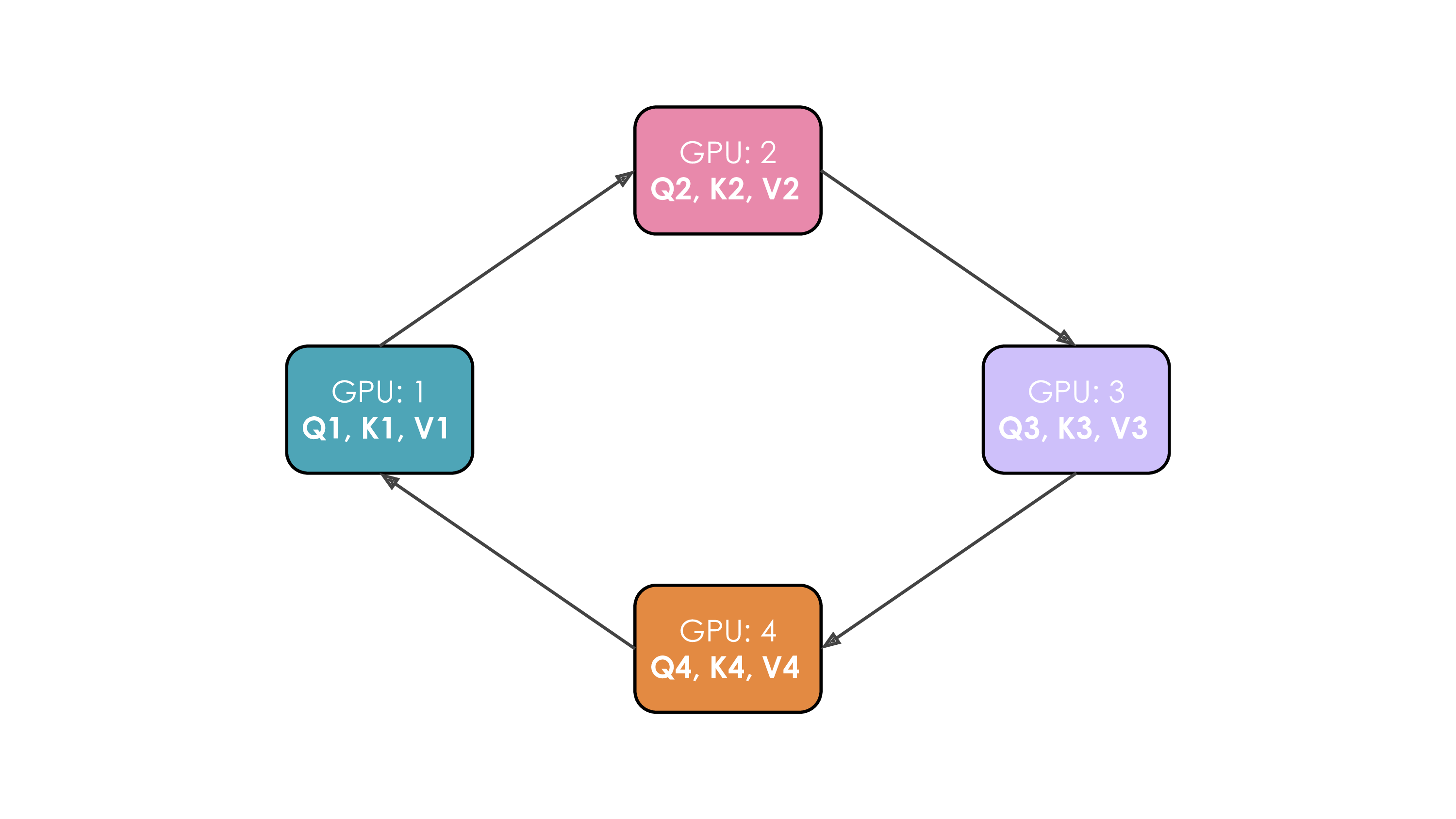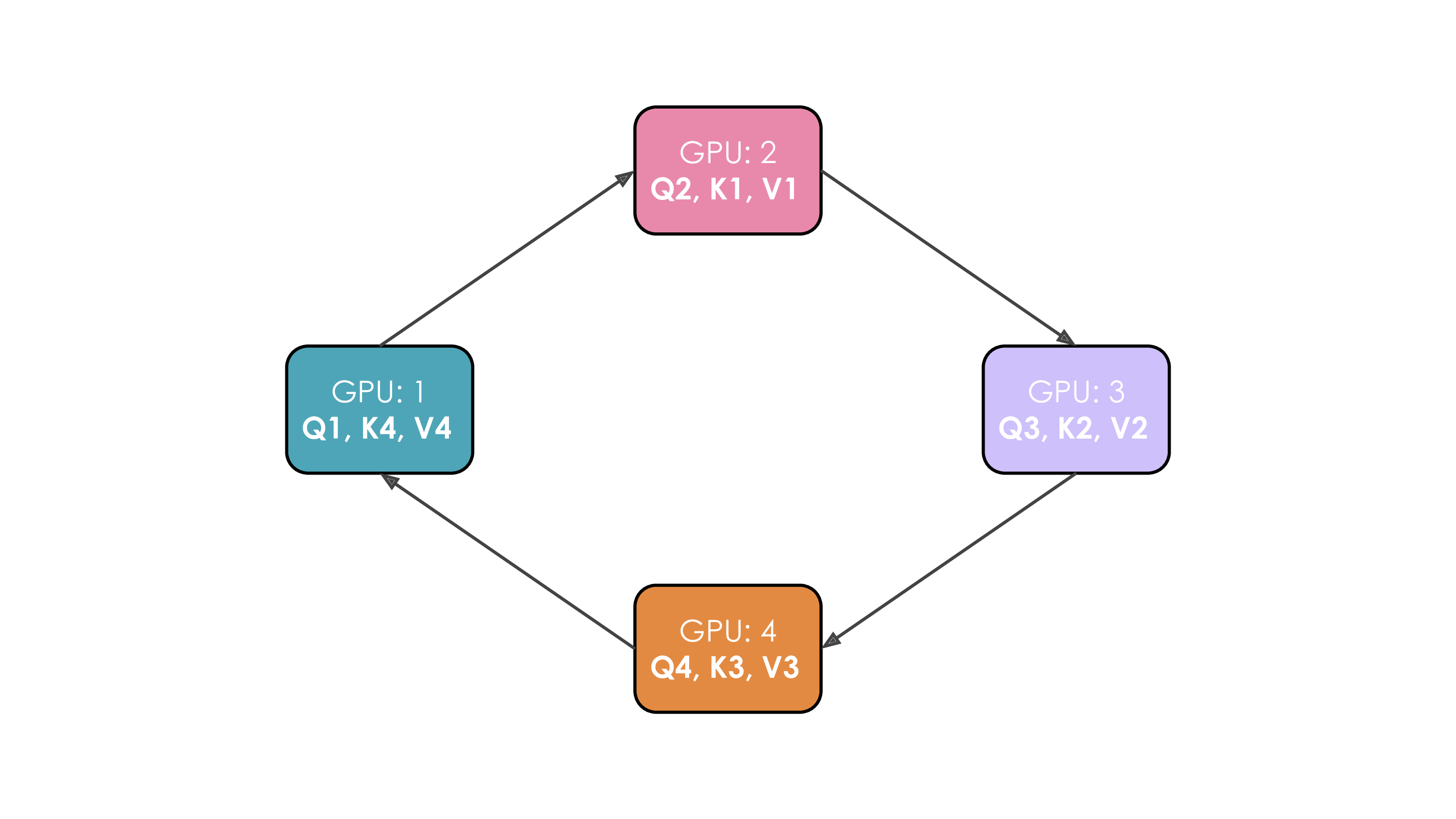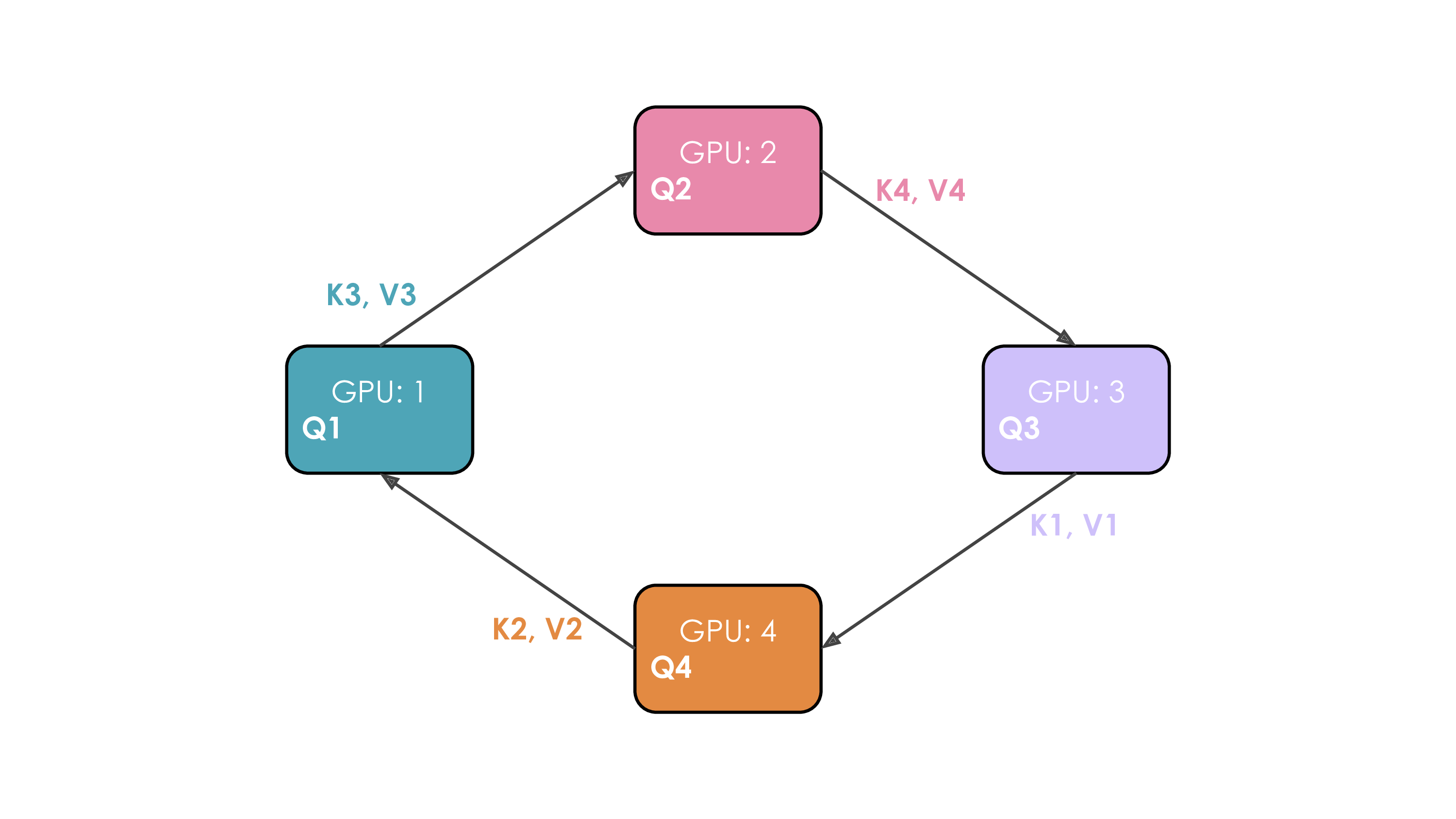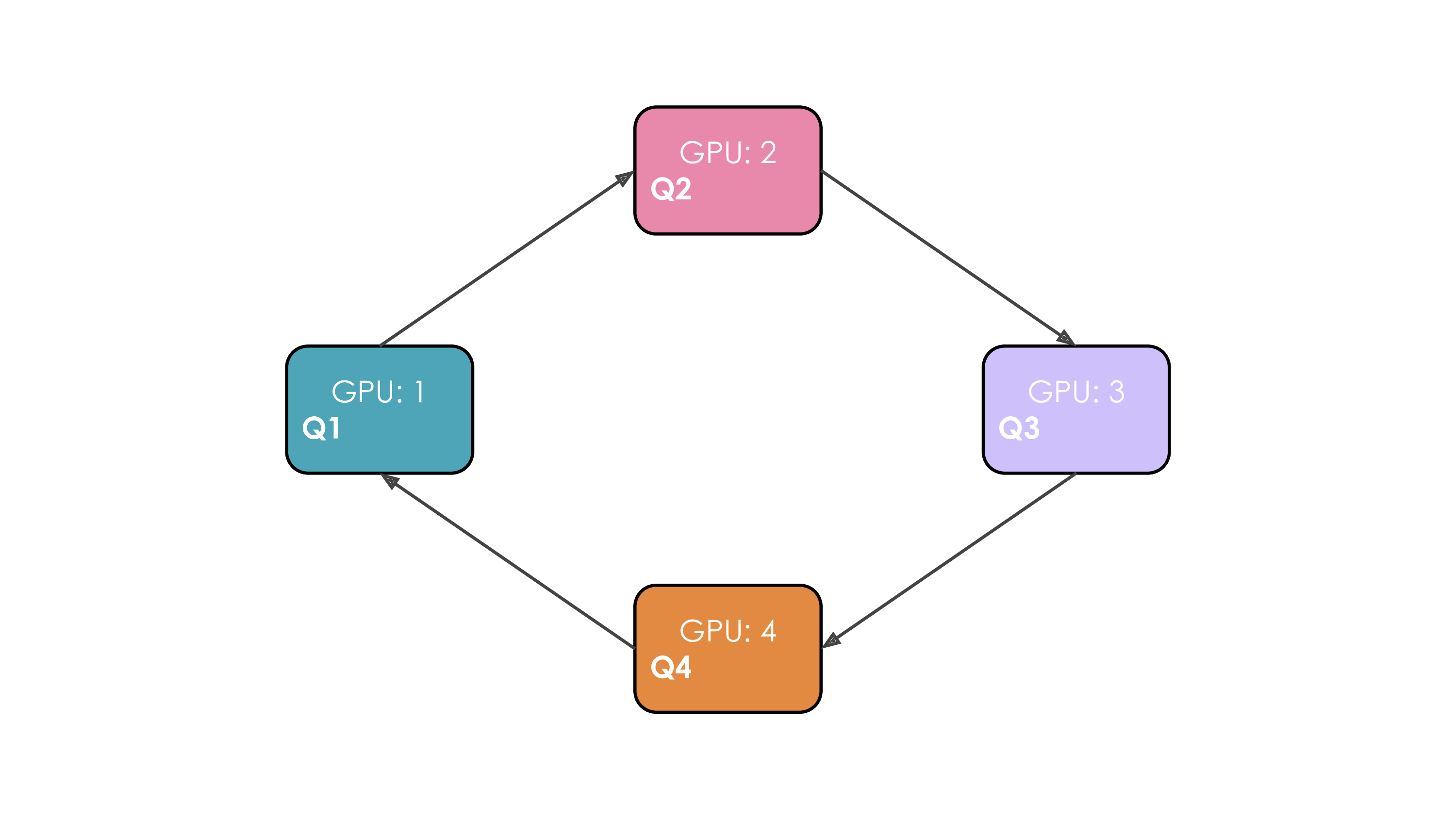
为了讲解方便,不妨设序列长度等于 GPU 数,也就是每个 GPU 只负责一个 Token,对应上面的矩阵就是每个 GPU 负责一行。
在初始情况,每个 GPU 只有自己的 $Q_i,K_i,V_i$ ,只能算出来对角线部分(加框的代表计算完成),这显然是不够的:
$$ \begin{bmatrix} \boxed{\text{Softmax}(Q_1\cdot K_1) \cdot V_1} & 0 & \cdots & 0\\ \text{Softmax}(Q_2\cdot K_1) \cdot V_1 & \boxed{\text{Softmax}(Q_2\cdot K_2) \cdot V_2} & \cdots & 0\\ \vdots & \vdots & \ddots & \vdots\\ \text{Softmax}(Q_n\cdot K_1) \cdot V_1 & \text{Softmax}(Q_n\cdot K_2) \cdot V_2 & \dots & \boxed{\text{Softmax}(Q_n\cdot K_n) \cdot V_n} \end{bmatrix} $$
因此,再算完第一步之后,每个 GPU 向下一个 GPU 传递自己的 $K_i,V_i$,这样下一个 GPU 就又多了可以计算的内容:
$$ \begin{bmatrix} \boxed{\text{Softmax}(Q_1\cdot K_1) \cdot V_1} & 0 & \cdots & \cdots & 0 \\ \boxed{\text{Softmax}(Q_2\cdot K_1) \cdot V_1} & \boxed{\text{Softmax}(Q_2\cdot K_2) \cdot V_2} & \cdots & \cdots & 0 \\ \text{Softmax}(Q_3\cdot K_1) \cdot V_1 & \boxed{\text{Softmax}(Q_3\cdot K_2) \cdot V_2} & \boxed{\text{Softmax}(Q_3\cdot K_3) \cdot V_3} & \cdots & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ \text{Softmax}(Q_n\cdot K_1) \cdot V_1 & \text{Softmax}(Q_n\cdot K_2) \cdot V_2 & \text{Softmax}(Q_n\cdot K_3) \cdot V_3 & \dots & \boxed{\text{Softmax}(Q_n\cdot K_n) \cdot V_n} \end{bmatrix} $$
像这样,将 $K_i,V_i$ 传递 $n$ 次,那么所有待计算的注意力矩阵元素就都计算好了。
以上流程叫做环形注意力(Ring Attention),示意图如下:
在线 Softmax
敏锐的读者应该发现,计算上面矩阵的 Softmax 时,必须要完整一行的 $Q_i\cdot K_i$ 结果算好了才能计算,那上下文并行怎么能做到一个个分量的分别计算呢?因此,在这里必须使用在线 Softmax 替换掉传统的 Softmax。
在线 Softmax 允许我们在只有局部数据的情况下,通过动态更新缩放因子,逐步收敛到全局正确的 Softmax 结果。
其核心在于维护两个额外的统计量:当前已见数据的最大值 $m$,当前已见数据的指数累加和 $d$.
当我们将两个局部计算结果(例如来自两个不同的 GPU 或两个数据块)合并时,计算如下:
假设旧状态为 $(m_{old}, d_{old})$,新到来的数据块状态为 $(m_{new}, d_{new})$:
- 更新全局最大值:$m_{combined} = \max(m_{old}, m_{new})$
- 对齐并更新累加和:为了保持数值一致性,旧的累加和需要根据新的最大值进行缩放 $d_{combined} = d_{old} \cdot e^{m_{old} - m_{combined}} + d_{new} \cdot e^{m_{new} - m_{combined}}$
上面的例子为了方便,每个 GPU 只负责一个 Token,在实际情况中每个 GPU 是对应多个 Token 的,如下面左图。可以明显看出,虽说每个 GPU 负责的 Token 数目是均衡的,但是由于注意力计算的平方特性,每个 GPU 的计算量是不同的,GPU 计算量和 Token 位置成正比增长。
为了实现计算量的平衡,可以采用下面右图的切分方式,叫做 Zig-Zag Ring Attention。这种方式中,每个 GPU 负责序列中点对称的前后两端 Token,这样就能实现 Token 数量和计算量二者的均分。
| Ring Attention | Zig-Zag Ring Attention |
|---|---|
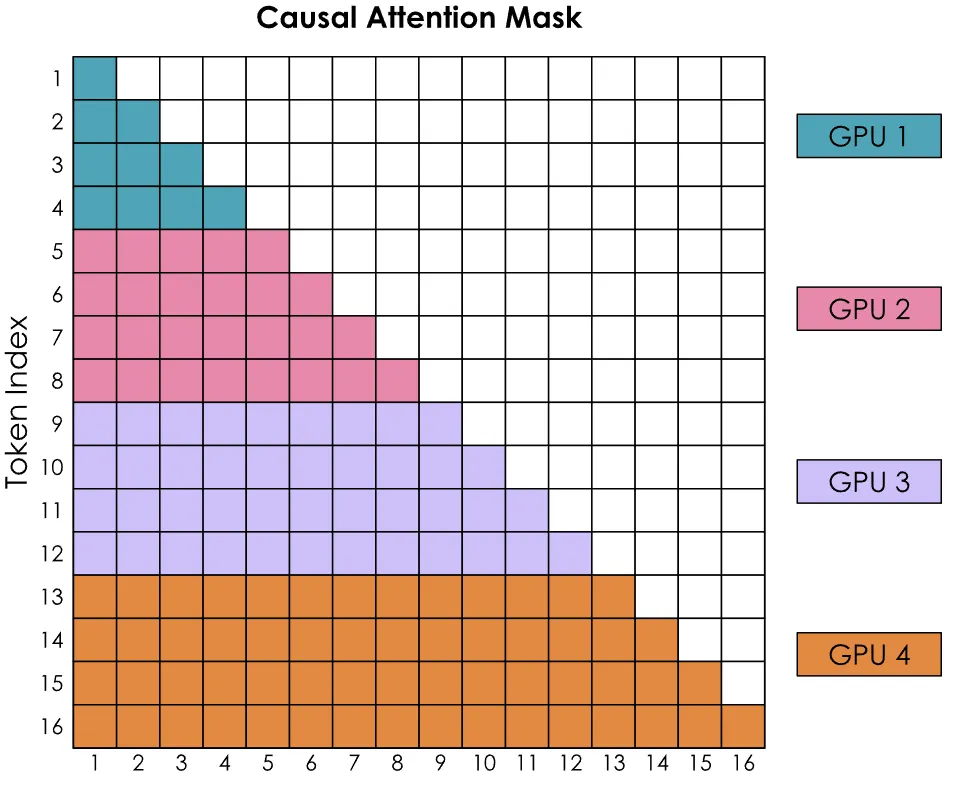 | 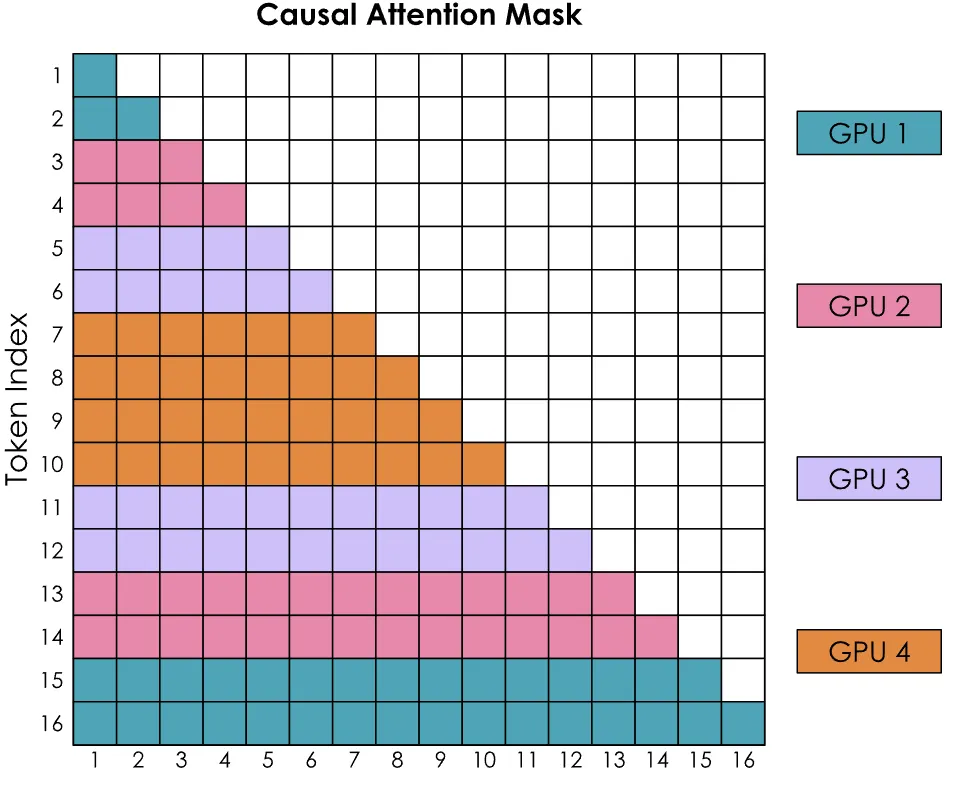 |
1.3 代价
使用环形注意力的上下文并行在注意力阶段会产生 P2P 的通信,每个 GPU 将自己的 K/V 块传递给下一个 GPU,同时接收上一个 GPU 的块。
但比较好的一点是,我们可以让计算和通信同时发生,在计算当前 $Q_i, K_i, V_i$ 时,就开始准备下一次计算的 $K_{i+1},V_{i+1}$,从而节省等待通信的时间,流程如下:

总的来说,上下文并行的通信开销处于数据并行和张量并行(数据并行<上下文并行<张量并行)之间,是大模型处理超长序列的必不可少的方法。
2 流水线并行 Pipeline Parallelism
2.1 概念
在大模型参数量越来越大的现在,超大参数量的模型已经无法在单台 8 卡的 GPU 节点运行了。例如 685B 参数量的 DeepSeek-V3.2,要运行它的 BF16 精度版本,仅仅储存模型参数都要约 1370GB 的显存,这种体量即使是 8 卡 H200 共 1128GB 的节点都没法运行。
上一篇文章介绍了张量并行,使用两台节点共 16 卡 H200 就可以解决这个问题。但是需要注意的是,张量并行的通信开销极其庞大,在单机 NVLink 内才能得到较好的速度。拓展到多机后,由于节点间的通信延迟大、速度慢,会导致显著的速度下降,浪费宝贵的 GPU 算力。
流水线并行(Pipeline Parallelism, PP)应运而生,它和张量并行一样可以在 GPU 间均摊显存,但是通信量显著降低,因此不仅可以在单机使用,也可以扩展到多机使用。它的核心思想是所有并行方法中最好理解的:把模型按层拆分。
如果一个模型有 64 层,我们有 4 块显卡,那么:
- GPU 0:负责第 1 到 16 层。
- GPU 1:负责第 17 到 32 层。
- GPU 2:负责第 33 到 48 层。
- GPU 3:负责第 49 到 64 层。
数据从第一块显卡开始处理,算完后将激活值(Activations)传给下一块显卡,直到最后一块显卡完成计算并得出 Loss,然后再反过来反向传播——就像流水线一样。
2.2 流水线气泡 (Bubble)
数据并行的最大难度在于如何解决流水线气泡 (Bubble),假设有一条数据要通过一个 16 层的 LLM,使用 4 卡流水线并行,每张卡分担 4 个模型层,那么一次完整的正反向传播如下图所示:
图片方格里的数字是模型层序号,表示的是数据通过不同的模型层。
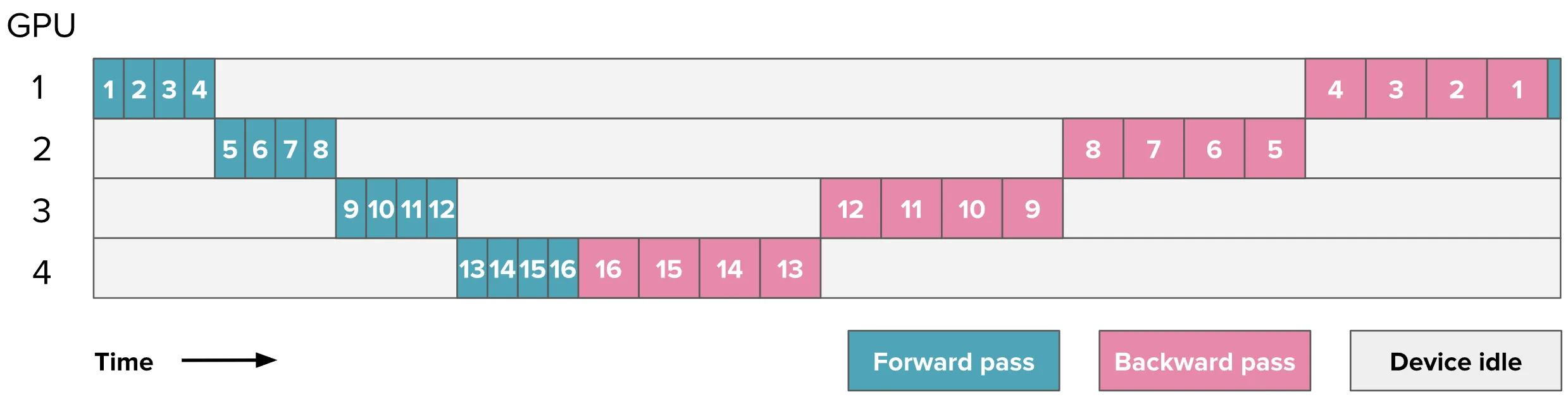
可以看出,在同一时间只有一块显卡在全速运转,其他显卡全部都在干等,大部分的算力都被白白浪费了。下面来看看不同方法的气泡情况。
2.2.1 All Forward, All Backward (AFAB)
如果到来了多个批次数据待处理,AFAB 将会首先做完所有数据的正向传播,然后再做所有数据的反向传播。图示如下:
从这里开始,图片方格里的数字是 Batch 序号,表示的是不同的数据正在计算。
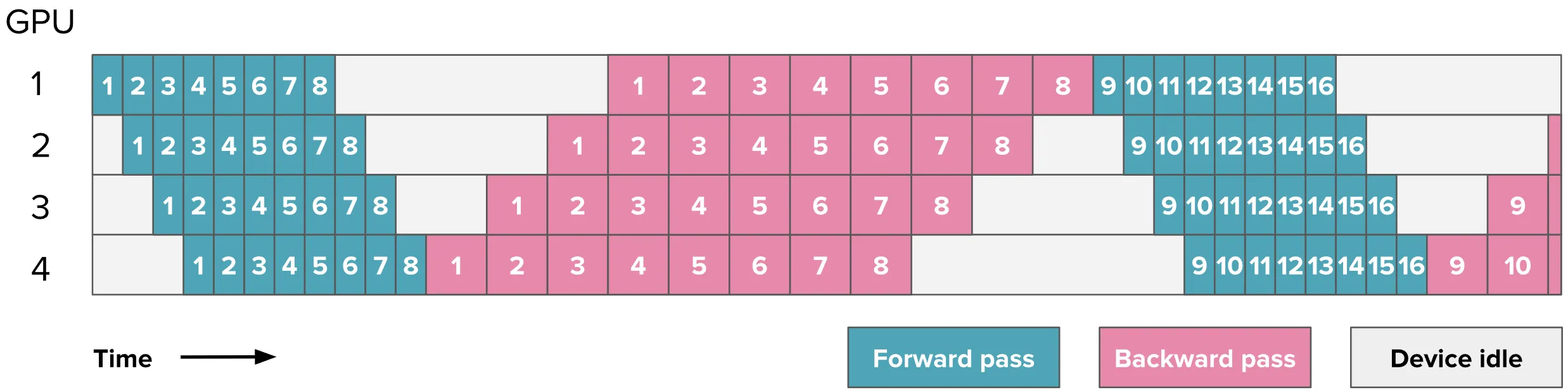
可以通过 GPU 空闲时间和运行实现的比值来评估该方法的效率,记 GPU 数量 $p$,同时处理的 Batch 数量 $m$,正向传播和反向传播的时间 $t_f,t_b$,那么:
$$ \text{Efficiency}=\frac{T_{\text{idle}}}{T_{\text{running}}}=\frac{(p-1)\cdot(t_f+t_b)}{m\cdot(t_f+t_b)}=\frac{p-1}{m} $$
通过公式看出,GPU 数量越多时并行效率越低,但可以通过提高同时处理的 Batch 数量来弥补。
但是可以同时处理的 Batch 数量不是无限多的,正向传播得到的激活值在反向传播完成计算前是不能丢弃的,当 Batch 数量增大时,需要同时储存的激活值会随着增大,最终会导致显存的耗尽。因此需要寻求其他解决方案。
2.2.2 One forward, One backward (1F1B)
如果到来了多个批次数据待处理,1F1B 在做完一条数据的正向传播后,会高优先级完成该条数据的反向传播。图示如下:
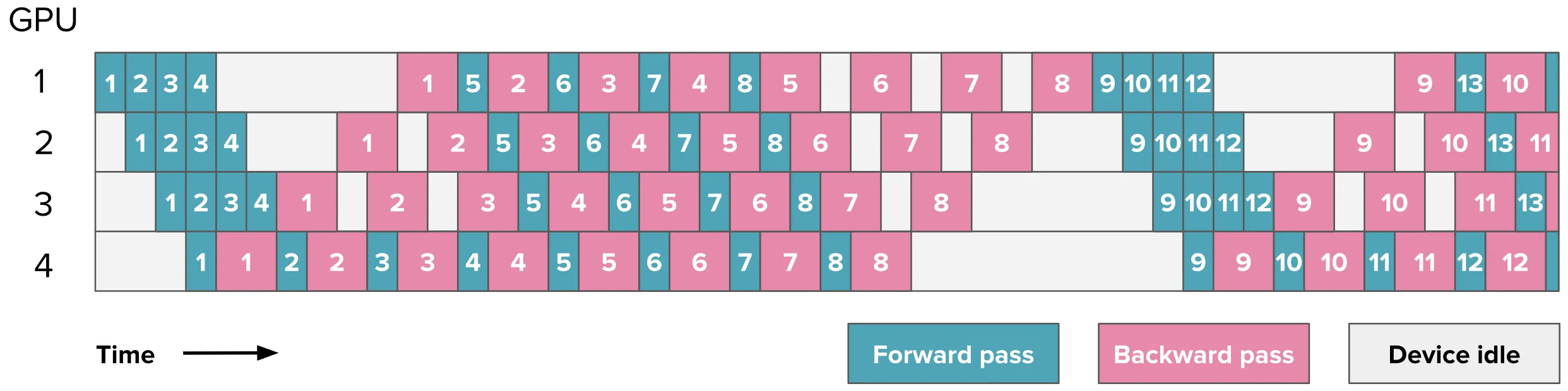
可以看到,当数据 $1$ 完成正向传播后,它立即开始了反向传播,数据 $2,3,4$ 的正向传播均开始排队,等待“见缝插针”。总结下来,1F1B 分为三个阶段:
- 热身阶段:GPU 会连续执行正向传播,直到填满流水线。
- 稳定阶段:GPU 进入 1F1B 循环。执行一个正向传播,执行一个反向传播。
- 收尾阶段:当所有正向传播完成后,GPU 连续执行剩余的反向传播。
把图示中的空白拼起来,其实可以发现 1F1B 和 AFAB 的效率其实是一样的($\frac{p-1}{m}$)。不同的是 1F1B 以高优先级完成每条数据的反向传播,确保每条数据的激活值以最快的可能被释放,从而可以通过更大的同时处理 Batch 数量来提升效率。
2.2.3 Interleaved Stages
该方法是 1F1B 的进一步优化版本。在标准的流水线并行中,每个 GPU 负责模型中连续的一段层:
- GPU 0:负责第 1 到 8 层。
- GPU 1:负责第 9 到 16 层。
而在 Interleaved(交错)模式下,每个 GPU 负责多个不连续的层段(切分两段为例):
- GPU 0:负责第 1 到 4 层和第 9 到 12 层。
- GPU 1:负责第 5 到 8 层和第 13 到 16 层。
图示如下:
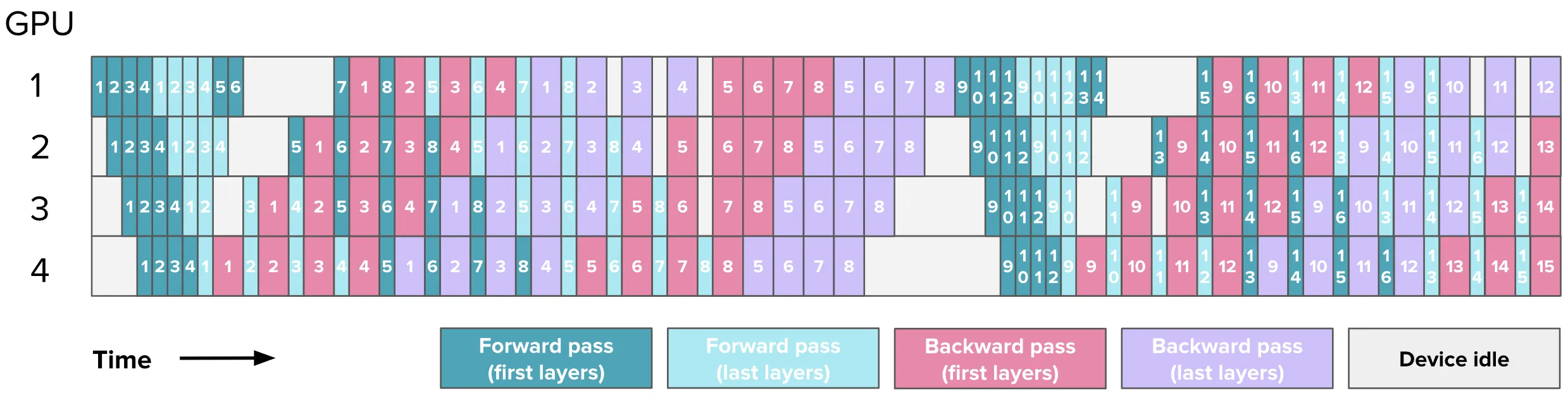
虽然总的计算量没变,但因为每个阶段变细了,流水线的启动延迟和收尾延迟都缩短了,相对于 1F1B 或 AFAB,Interleaved Stages 的效率为(记切分次数 $v$):
$$ \text{Efficiency}=\frac{T_{\text{idle}}}{T_{\text{running}}}=\frac{\frac{(p-1)}{v}\cdot(t_f+t_b)}{m\cdot(t_f+t_b)}=\frac{p-1}{vm} $$
可以看到,如果我们将模型拆得越细($v$ 越大),气泡就越小。不过没有免费的午餐,该方法中每个 GPU 之间每条数据要产生 $v$ 次通信,因此 $v$ 增大也会随之增大通信开销。
2.3 代价
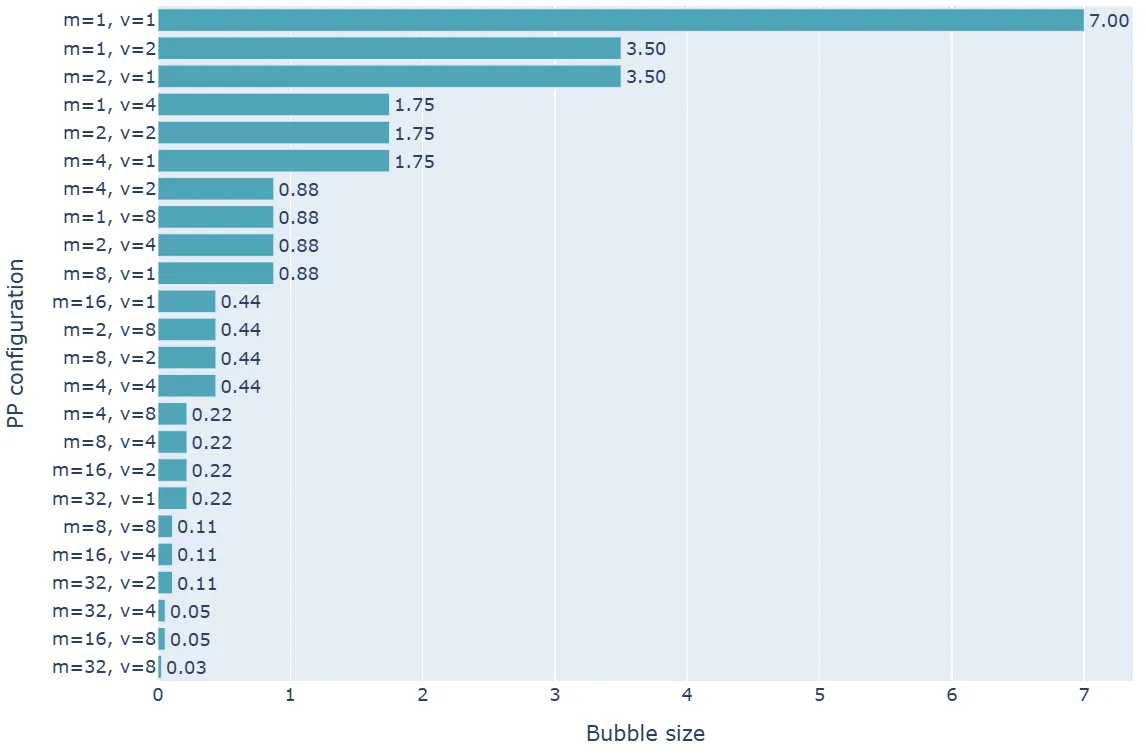
流水线并行是跨机通信代价最小的并行方法,让多机运行超大参数语言模型成为了可能。它的最大代价在于流水线气泡,不过通过上面介绍的方法,流水线气泡是可以被控制在合理范围内的:
3 专家并行 Expert Parallelism
3.1 概念
随着混合专家模型 (MoE) 的提出,专家并行应运而生,它就是专为 MoE 模型定制的并行方法。
它的思想也非常简单,它将不同的专家放置在不同的 GPU 上,Router 为每个 Token 选择将要处理它的一个或几个专家,然后将 Token 发送到对于专家的 GPU 上。
另外,MoE 模型不是所有层都是专家层,目前主流的是 FFN 部分是专家网络,其他部分都是普通的网络。因此专家并行通常和数据并行一同使用:
- 普通层:如 Self-Attention 层,所有 GPU 拥有一模一样的参数,采用标准的数据并行。
专家层:如 Feed-Forward 层,每个 GPU 只负责一部分专家的计算
- GPU 0 拥有专家 1 和 2。
- GPU 1 拥有专家 3 和 4。
- ...
3.2 方法
当数据流向专家层时,会发生以下过程:
- 路由:每个 GPU 上的 Router 计算出自己手里的 Token 应该去哪个专家那里。
- 分发:通过 All-to-All 通信,将 Token 发送到对应的 GPU 上。
- 局部计算:每个 GPU 并行地运行自己持有的专家模块。
- 收集:计算完成后,再次通过 All-to-All 通信,将结果传回原来的 GPU,以维持 Token 的原始序列顺序。
很容易想到,不同专家之间的负载不一定是均衡的,很有可能所有 Router 都把 Token 发给同一个专家,某个 GPU 上的专家过载了而其他 GPU 却空闲。不过这些内容在我之前的笔记《混合专家模型》中已经涉及,因此这些细节不再重复展开:https://io.zouht.com/192.html
3.3 代价
专家并行每个 Token 在每个专家层会发生两次 All-to-All 通信,它的开销属于中等的,尽管没有张量并行那么夸张的通信量,但也比流水线并行的通信量大多了,因此它仍然不建议在多机环境下使用。
本文采用 CC BY-SA 4.0 许可,本文 Markdown 源码:Haotian-BiJi