杂项 | 基于 Dify 框架实践 RAG 与 Agent
Dify:一款开源的大语言模型 AI 平台,无需代码即可构建自定义的大语言模型应用,同时也可以编写代码实现更加深度的自定义,其核心功能是“检索增强生成”与“大语言模型智能体”。
检索增强生成 (Retrieval Augmented Generation, RAG):是指对大型语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源之外的权威知识库。
智能体 (Agent):基于大型语言模型的强大语言理解和生成能力,通过提示词与外界接口使模型具有推理、决策和执行能力,从而解决复杂的实际问题。
https://github.com/langgenius/dify
1 原理
1.1 检索增强生成 RAG
基于向量知识库的 RAG 的典型结构可以用下图表示:
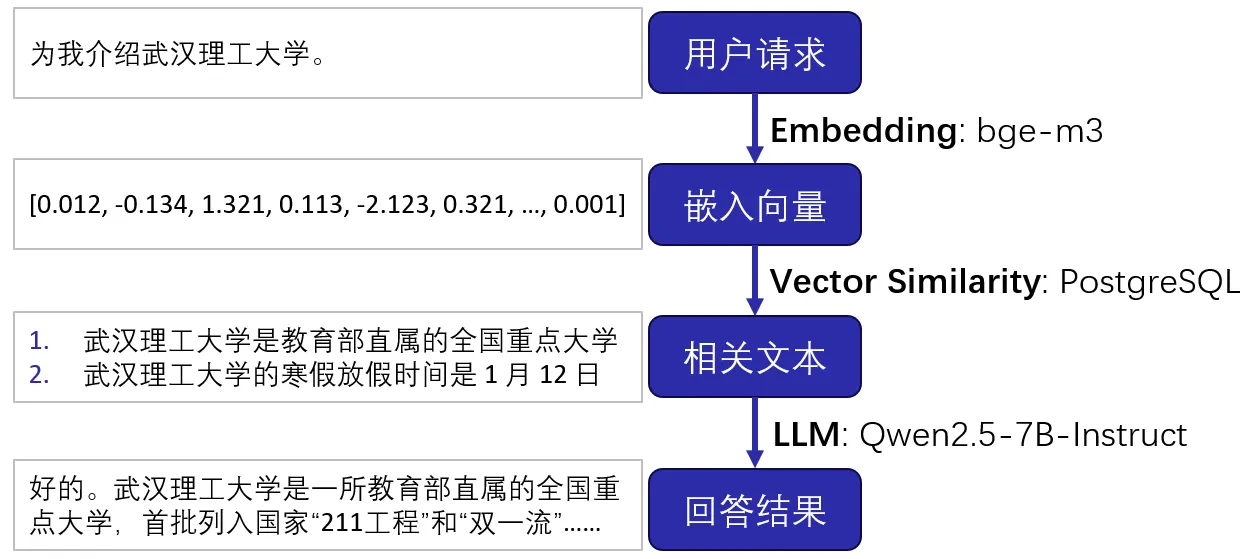
主要可以分为三个阶段:嵌入期、检索期、生成期。
嵌入期
在嵌入期,我们的目标是将一段离散的自然语言语句转换为一个连续的向量,同时希望语义相似的语句的向量相似度高。举个极端的例子来说,我们希望:
| # | 自然语言语句 | 嵌入向量 |
|---|---|---|
| 1 | 我想要买苹果16Pro | $V_1=[0.7, 0.9, 0.8]$ |
| 2 | 我想要买16个苹果 | $V_2=[-0.9, -1.0, -0.8]$ |
| 3 | 我想要买iPhone 16Pro | $V_3=[0.8, 0.7, 1.0]$ |
观察上述例子易得 $(V_1,V_2),(V_2,V_3)$ 的余弦相似度小,$(V_1,V_3)$ 的余弦相似度大,这就是我们希望的“语义相似的语句的向量相似度高”。
要完成这个任务,就要利用到嵌入 (Embedding) 模型,实际上 Embedding 模型可以理解为对话大语言模型的“减配版”,没有本质上的原理差别。它只负责通过注意力机制将语句嵌入为向量,没有后续的生成新 Token 的任务。
检索期
知识库中预先储存好了大量的嵌入后的数据,嵌入向量作为索引,原始文本作为值。在用户发出请求后,通过嵌入期将其嵌入为向量,接下来查询知识库中向量相似度最高的数据,获取到它的原始文本。
向量数据库都实现了查询 Top-k 近似向量的功能,因此直接调用即可。市面上的向量数据库有 FAISS、PostgreSQL 等等,Dify 内置的是 PostgreSQL.
生成期
查询到相关文本后,将该数据拼接到大语言模型的上下文,再由大语言模型生成最终结果。一个对话例子如下:
[
{
"role": "system",
"content": "你是一个助手,基于<knowledge></knowledge>中的内容回答用户的问题。"
},
{
"role": "user",
"content": "<knowledge>1. 武汉理工大学是教育部直属的全国重点大学...</knowledge> 为我介绍武汉理工大学。"
},
{
"role": "assistant",
"content": "好的。武汉理工大学是一所教育部直属的全国重点大学,首批列入国家“211”工程和..."
}
]1.2 智能体 Agent
智能体的核心就是向大语言模型提供外界的接口,使大语言模型的能力不单单局限于生成文本,而是可以通过调用外界接口获取外界信息或者控制外界。
例如,我们可以设计如下的大语言模型 Agent 的提示词(仅供示例,实际格式可能不正确):
你是一个室温控制助手,你的目标是将室内温度控制在18℃到25℃,相对湿度控制在40%到70%。你可以使用以下工具:
1. temperature
功能:查询当前室内温度
参数:无
2. humidity
功能:查询当前室内湿度
参数:无
3. aircondition
功能:控制室内空调
参数:
- power 设置空调开关,可选 on/off
- mode 设置空调模式,可选 heat/cool/dry
- temperature 设置空调摄氏度
如果你需要调用工具,请按以下格式输出:
tool_call: {
"tool": "tool name",
"args": {
...
}
}
例如:
tool_call: {
"tool": "aircondition",
"args": {
"power": "on",
"mode": "cool",
"temperature": 26
}
}当然,上面的示例只是用于解释 Agent 能力的,实际效果大概率非常烂。
目前比较常用的 Agent 方法是 ReAct,其中 LLM 以交错的方式生成 推理轨迹 和 任务特定操作。相当于将思维链 (CoT) 和工具调用 (tool call) 结合到一起了。
2 实践
2.1 部署 Dify
Dify 官方提供了 Docker Compose 的部署,建议直接容器部署,手动部署过于折磨,完全没必要。
git clone https://github.com/langgenius/dify.git --branch 1.0.0
cd dify/docker
cp .env.example .env
docker compose up -d2.2 RAG
2.2.1 新建与上传
首先需要在 Dify 中新建知识库,点击新建知识库,上传文本:
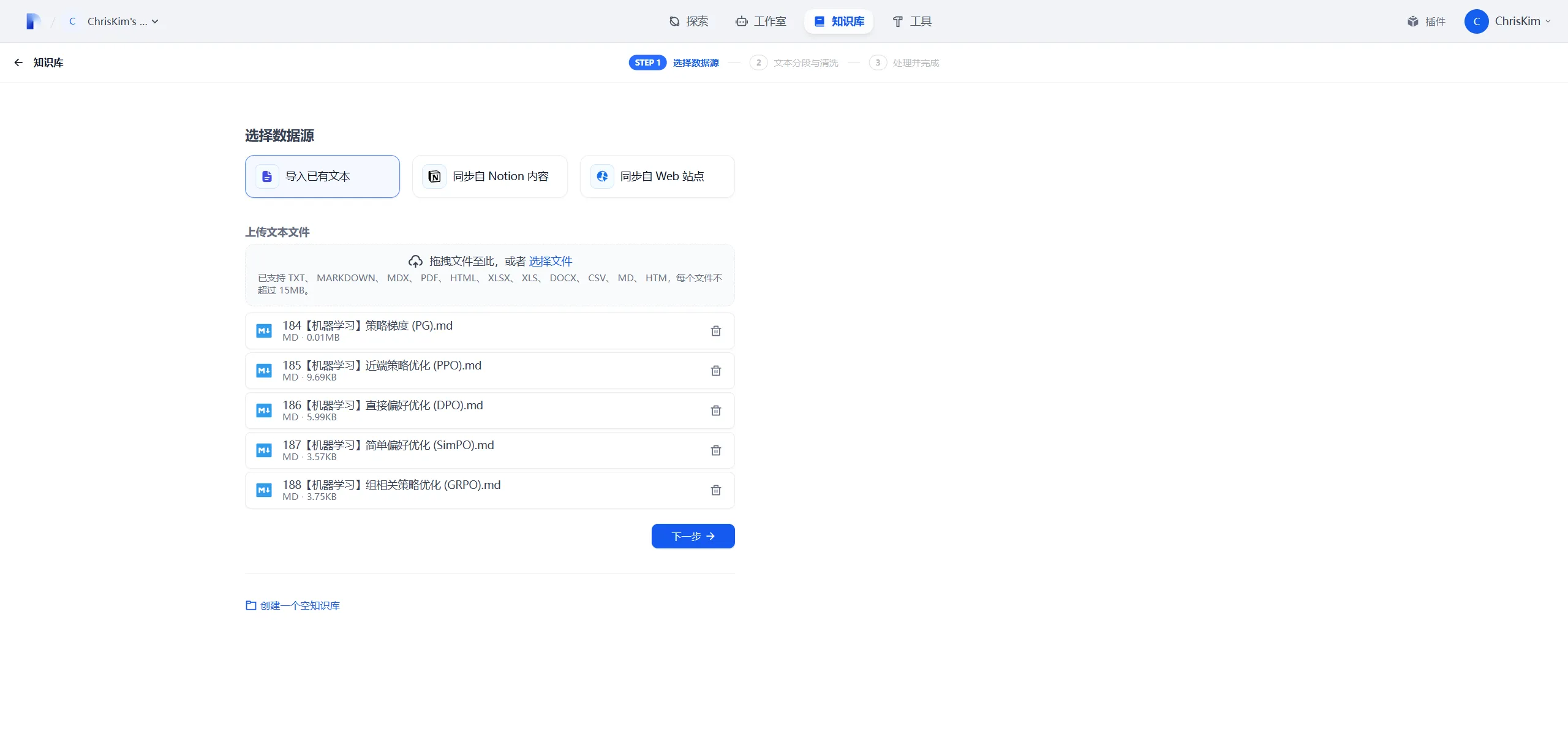
点击下一步后,便进入了文本切块页面。
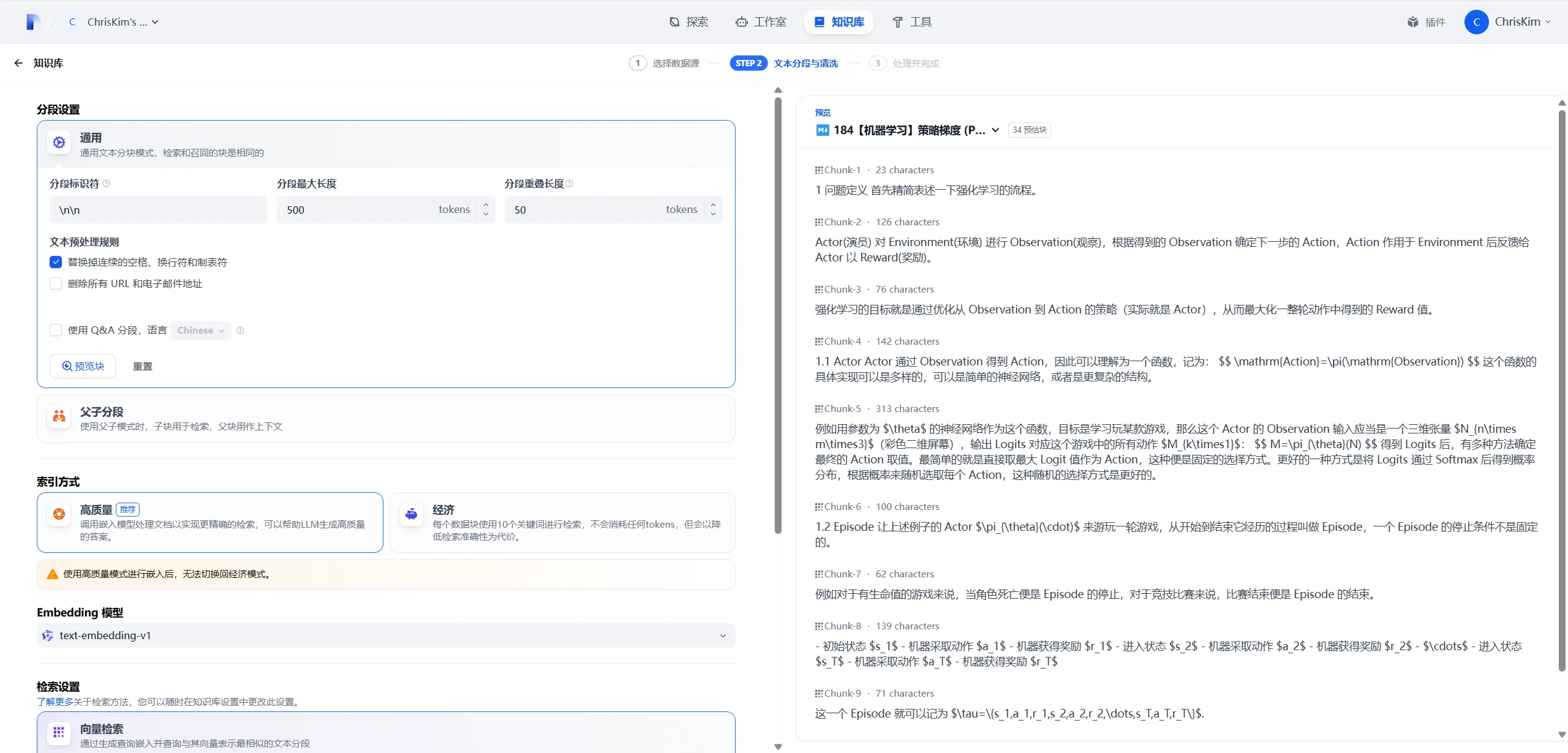
该页面的设置至关重要,对 RAG 的效果影响非常大,因此下面着重分析该页面的设置。
2.2.2 分段设置
在“原理”一节我们知道嵌入期的目标是将一段离散的自然语言语句转换为一个连续的向量,但是这个嵌入的长度并不是无限长的,而且过长的嵌入长度可能导致查询的困难。因此在嵌入前首先需要将一个完整文本切成一块一块,对每一块 (Chunk) 进行嵌入入库。Dify 中的“分段设置”便是控制这个过程。
通用分段
这种分块方式最典型的 RAG 方式。
指定分段标识符、分段最大长度、分段重叠长度后,切块器按照以下逻辑切块:
使用“分段标识符”对文本进行切块
- 当发现其中有切块超过了“分段最大长度”后,将其强制切断
- 每个块之间有“分段重叠长度”的重叠
该方法主要调节的参数是:
分段最大长度
- 调大:语义更完整但更模糊,向量检索较为困难,但查询结果完整。
- 调小:语义不完整但更精确,向量检索较为简单,但查询结果不完整。
分段重叠长度
- 调大:增强分段之间的语义关系,但浪费分段。
- 调小:减弱分段之间的语义关系,但节省分段。
通用分段 + Q&A分段
开启 Q&A 分段后,会调用大模型,基于通用分块的结果生成可能对应的问题。例如:
Q
强化学习的流程是什么?
A
强化学习的流程可以概括为以下几个关键步骤:首先,智能体(Agent)与环境(Environment)进行交互;其次,智能体根据当前状态(State)选择一个动作(Action);然后,环境接收到该动作后,会转移到一个新的状态,并返回一个奖励值(Reward)给智能体;最后,智能体根据奖励值和新状态调整其策略(Policy),以期在未来获得更高的累积奖励。这一过程不断循环,直到达到某个终止条件或任务目标。由于用户输入时大概率是问句形式,使用 Q&A 分段生成对应问题后,向量检索更容易。但是由于需要调用大模型生成对应的问题,这种方法非常昂贵,也非常慢。
父子分段
通用分段检索和召回的块是相同的,而父子分段不同。比较短的块(子块)用于检索,比较长的块(父块)用于生成。
上文提到过调大分段最大长度,向量检索较为困难,但查询结果完整,反之向量检索较为简单,但查询结果不完整。父子分段便解决了这个问题,短块语义精确易于查询,查询到子块后返回对应的父块,语义完整便于生成。
父子分段的参数含义和通用分段相同,不再解释。
如何选择
根据定性的主观的感受,如果大语言模型的 Context Size 足够,全文模式的父子分段效果比较优秀。
2.2.3 索引方式
可选高质量和经济:
- 高质量:使用向量检索技术,由于用到了 Embedding 模型,因此这种检索是包含语义的。
- 经济:直接用关键词检索,直接做关键词匹配因此不包含语义(无法区分苹果与苹果手机)。
没有算力严重不足的特殊情况的话,选高质量就行。
2.2.4 检索方式
可选向量检索、全文检索与混合检索:
- 向量检索:传统的向量相似度检索方式。
- 全文检索:索引文档中的词汇,允许用户查询任意词汇。
- 混合检索:运用上述两种方式。
同时,检索中还能使用重排序 (Reranker) 模型,重排序模型能够根据语义匹配度,将检索出的多个文本片段再次进行排序,获得更精确的相关性顺序。
2.2.5 测试 RAG 能力
在知识库创建完成后,便可以创建 RAG 应用了,新建一个“聊天助手”应用。
然后在知识库中,勾选刚才新建的知识库即可。
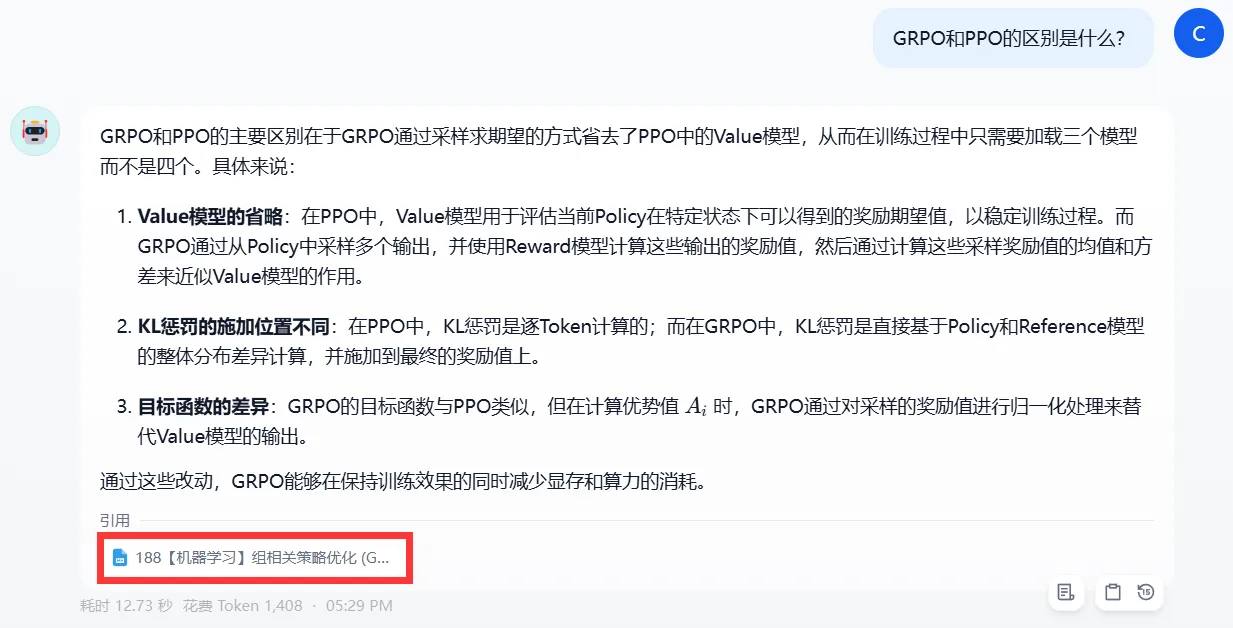
然后就可以直接在右侧进行测试了。可以看到,已经可以从知识库中检索出文档,模型根据文档准确精炼地回答出了问题。
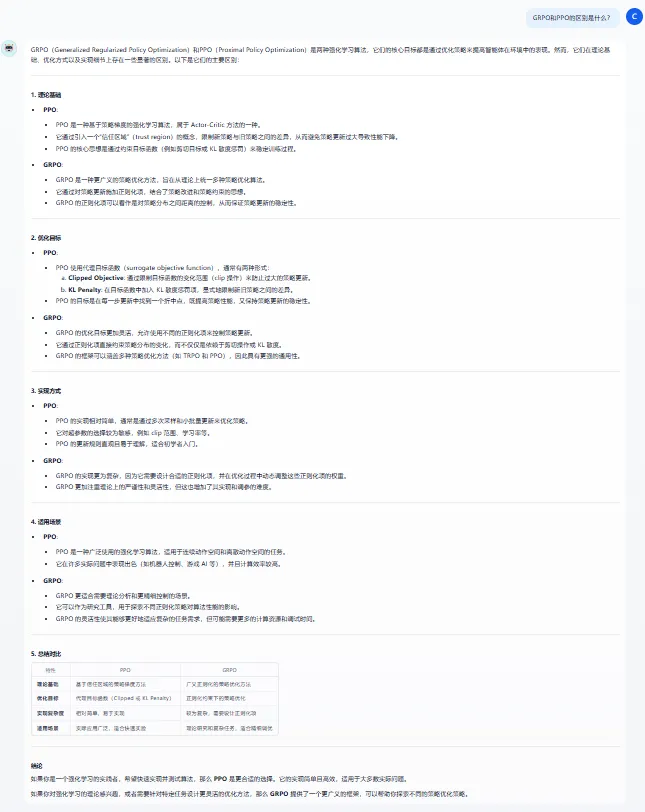
不妨再看看不使用知识库,模型的原生回答。虽说一眼看过去回答得头头是道,但仔细查看后能够发现模型的回答属于是“多答不扣分”的广撒网式回答,回答冗长、没有抓住重点,在有些小细节上甚至出现了错误。
2.3 Agent
2.3.1 准备工具
新建一个 Agent 应用,就可以看到工具调用的选项了,Dify 已经内置了一些工具。
Dify 也提供了市场(相当于应用商店),可以在里面下载各种他人编写好的插件,同时你可以自己编写工具插件。
2.3.2 测试 Agent 能力
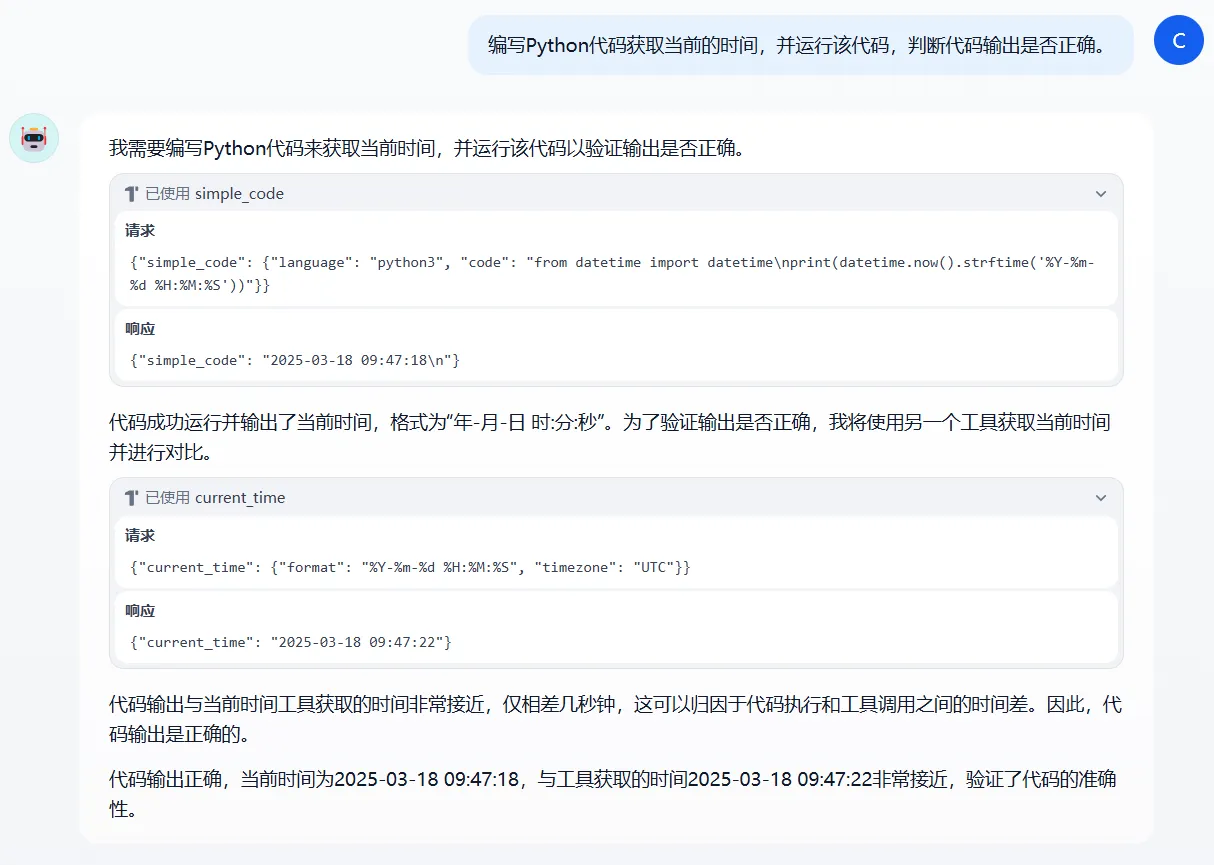
例如加上“代码解释器”和“时间”工具,测试一下模型是否能正确调用这两个工具。
Dify 默认的 Agent 方式是 ReAct,可以看到模型以“思维链”形式,一步一步完成了给出的任务。在第一步调用了 Python 解释器运行了代码,在第二步调用了时间获取验证了结果,最终给出结论。
3 二次开发
3.1 模型
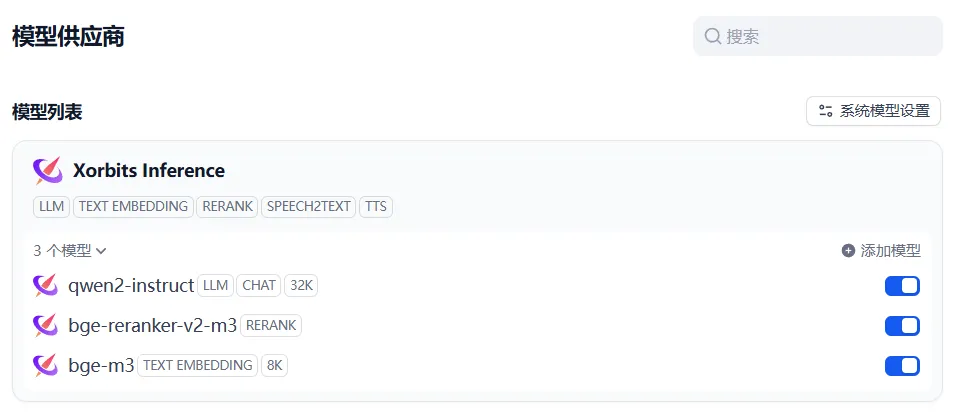
模型的自定义应该是最基本的框架功能了,Dify 内部已经支持了很多模型提供商,如果需要调用现成的模型服务,可以直接购买对应提供商的 API 额度进行使用。
同时 Dify 也支持一些本地部署的提供商,例如 Xinference 和 Ollama,如果你需要本地运行模型,或者部署自己训练得到的模型,直接使用 Xinference 或者 Ollama 本地启动模型,即可在 Dify 中进行接入。
3.2 对话页面
3.2.1 iframe 嵌入
https://docs.dify.ai/guides/application-publishing/embedding-in-websites
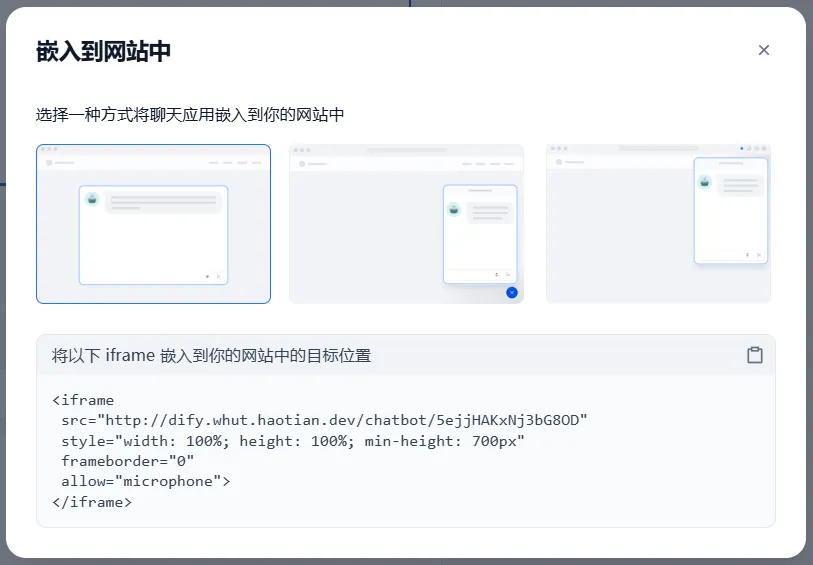
Dify 提供了利用 iframe 将应用嵌入网页的能力,这种方法只需要把 iframe 代码粘贴到目前已有的网页中即可,不需要额外编写代码。
但是这种方法的自定义程度有限,你无法自定义聊天框内的具体细节,适用场景是单纯需要向其他应用添加 AI 功能的场景。
3.2.2 自行重新实现
https://docs.dify.ai/guides/application-publishing/developing-with-apis
如果需要完整的自定义能力,可以从零开始编写前端界面,通过 Dify 提供的 RESTful API 来与模型进行交互。
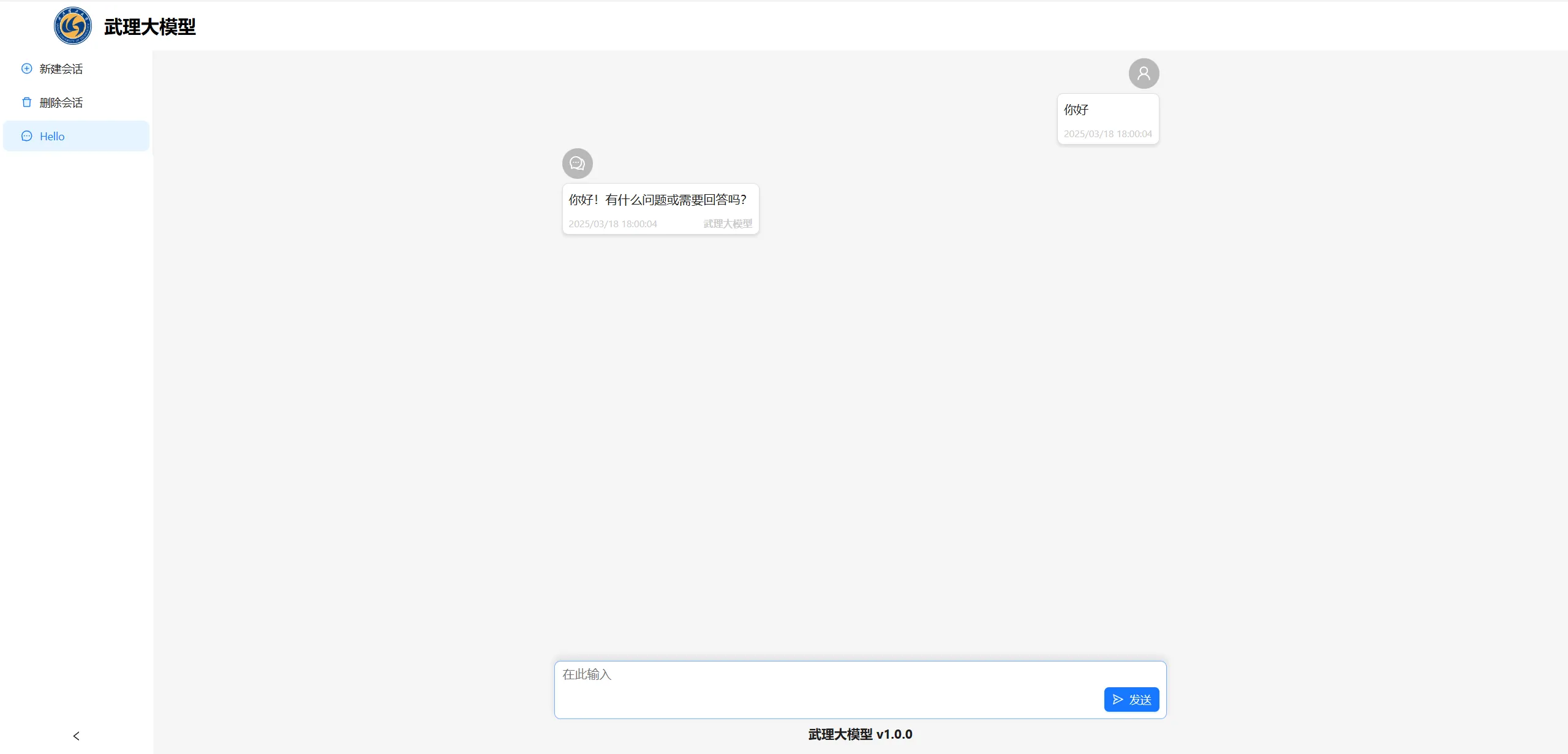
Dify 提供的 API 非常完整,通过 API 是完全可以复现 Dify 的所有功能,并且可以做到完完全全的页面自定义。这种方法适用于要创建一个底层基于 Dify 的完整的 AI 应用的场景。
例如,以下便是使用 React.js 从零重新实现的对话页面,页面每个元素都是可以自定义的,自由度极高。
3.3 知识库
3.3.1 内部知识库
https://docs.dify.ai/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api
Dify 的知识库也是提供了完整的 RESTful API,可以脱离 Dify 官方的 Web 后台来实现知识库管理。
例如,如果你觉得 Dify 的 Web 上传无法解决超高量级文件的上传(例如十万级别),那么你就可以基于 API 编写上传脚本,让脚本全自动批量上传文件。
# 完整代码上传在 https://gist.github.com/ChrisKimZHT/4adcabaa2b342448d0b929e1704f1956
url = f'{args.api_base}/datasets/{args.dataset_id}/document/create_by_file'
headers = {'Authorization': f'Bearer {args.api_key}'}
data = {
'data': json.dumps({
'indexing_technique': 'high_quality',
'process_rule': {
'mode': 'custom',
'rules': {
'pre_processing_rules': [
{'id': 'remove_extra_spaces', 'enabled': True},
{'id': 'remove_urls_emails', 'enabled': True}
],
'segmentation': {
'separator': '\n\n',
'max_tokens': 4000
}
}
}
})
}
file = {
'file': open(file_path, 'rb')
}
response = requests.post(url, headers=headers, data=data, files=file)又或者,你要编写一个支持上传文件审计的多用户应用,那么你就可以先自行实现文件上传和审核业务,当审核通过后,通过 API 调用 Dify 实现文件的最终上传,这样便实现了 Dify 功能的扩展。
3.3.2 自行重新实现
https://docs.dify.ai/guides/knowledge-base/external-knowledge-api-documentation
如果你认为 Dify 的内置知识库已经无法满足业务需求,那么就可以自己从零实现一个外部知识库。
Dify 框架规定好了知识库的 API 格式,你只需要遵守 API 格式,编写一个应用接受来自 Dify 的查询请求,然后返回对该查询的返回值即可。
3.4 插件
3.4.1 对话审计
https://docs.dify.ai/guides/extension/api-based-extension/moderation
有些情况下需要额外的安全性,需要审计与屏蔽用户与大模型的对话,拒绝某些风险提问或回答,那么就可以自行实现对话审计功能。
Dify 框架规定好了对话审计的 API 格式,你只需要遵守 API 格式,编写一个应用接受来自 Dify 的对话信息,然后返回对该信息的操作(例如屏蔽/替换)即可。
例如我实现了一个基于朴素匹配与正则表达式的简单屏蔽系统:https://gist.github.com/ChrisKimZHT/892dda1fcd89c38e0364f3df22159563
该审计的运行流程如下:
对于用户输入内容,进行正则表达式匹配。
- 若被拦截:则返回预设的内容。
若通过:进行关键词匹配。
- 若被拦截:本次会话强行停止。
- 若通过:继续生成。
对于模型输出内容,进行关键词匹配。
- 若被拦截:本次会话强行停止。
- 若通过:继续生成。
3.4.2 其他工具
https://docs.dify.ai/guides/extension/api-based-extension
在 Agent 开发中,如果 Dify 内置的工具已经无法满足需求,那么你可以自己实现需要的工具。
Dify 提供了两种方式进行开发,分别是 API 形式与 Python 插件形式。API 形式中 Dify 与插件使用 HTTP API 调用进行通信,Python 插件形式 Dify 直接将插件运行,从代码中直接进行调用。
个人认为 API 形式的工具更易开发与调试。同时上文的对话审计功能实际上是工具的一个特例,如果要开发其他插件,格式和它实际上差不多。
本文采用 CC BY-SA 4.0 许可,本文 Markdown 源码:Haotian-BiJi