机器学习 | 视觉语言模型 (VLM)
视觉语言模型 (Vision Language Model, VLM):能够同时理解文本和图像的多模态大语言模型,输入为图像和文本,输出为文本。
本文介绍的 LLaVA 架构是最经典的 VLM 架构,当前的模型大多基于该架构进行进一步优化。原始论文:Visual Instruction Tuning .
1 方法思路
对于单模态大语言模型,生成的流程如下:
- 使用 Tokenizer 对文本 Tokenize 获得 Token 序列;
- 对 Token 进行 Embedding 得到 Embedding 序列;
- 将 Embedding 序列输入 LLM Decoder 预测下一个 Token;
- 将预测的 Token 尾接到 Token 序列,返回步骤 1 继续自回归生成,直到终止 Token。
可以发现,即使是单模态语言模型,输入 LLM 也并不是文本,而是经过处理后的特征序列——Embedding 序列。那么如果能用一些方法,将图片编码成和文本相同的特征序列,那么就可以让大模型支持图片的输入,并且可以复用整个 LLM Decoder 架构,非常优雅。
“将图片编码为特征”这个任务已经有很多研究,可以直接复用相关模型,LLaVA 架构便是使用的预训练 CLIP 模型的 Image Encoder 作为视觉编码器,使用 Vicuna 作为大模型。
还有个细节是,视觉编码器的特征维度往往和大模型不同,并且特征没有对齐,因此需要加一个连接层对齐维度和特征,通常由 MLP 完成。
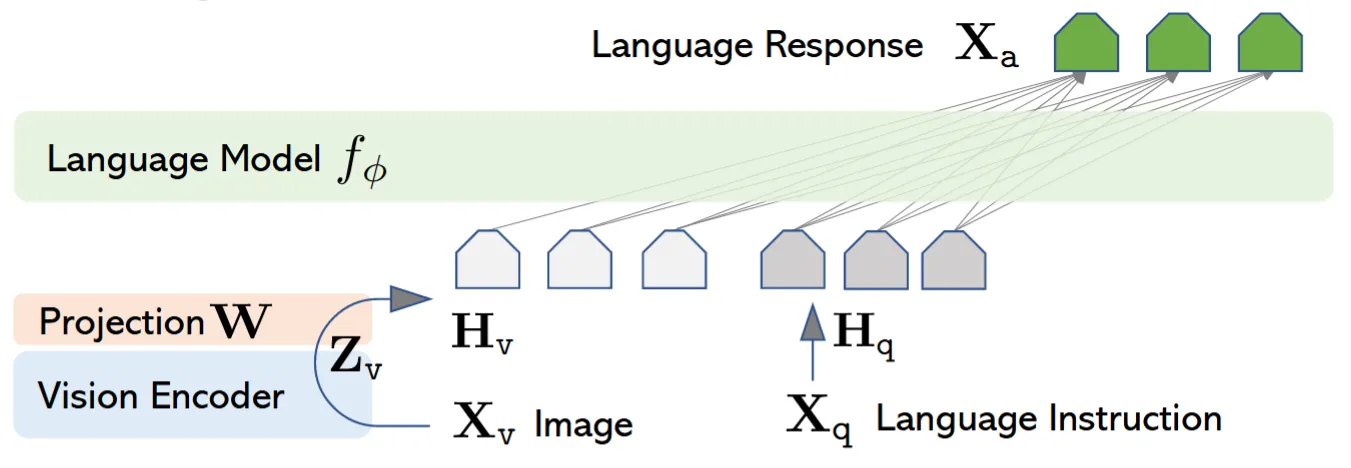
图片来源:Visual Instruction Tuning
2 公式细节
文本编码
对于文本模态 $\mathrm{\boldsymbol{X}}_{\mathrm{text}}$,首先通过 Tokenizer 切分获得文本 Token 序列:
$$ \mathrm{\boldsymbol{T}}_{\mathrm{text}}=\mathrm{Tokenizer}(\mathrm{\boldsymbol{X}}_{\mathrm{text}}) $$
然后使用嵌入表将 Token 序列编码为文本特征序列:
$$ \mathrm{\boldsymbol{H}}_{\mathrm{text}}=\mathrm{Embedding}(\mathrm{\boldsymbol{T}}_{\mathrm{text}}) $$
图片编码
对于图片模态 $\mathrm{\boldsymbol{X}}_{\mathrm{vision}}$,首先切分为 Patch 序列:
$$ \mathrm{\boldsymbol{P}}_{\mathrm{vision}}=\mathrm{Patching}(\mathrm{\boldsymbol{X}}_{\mathrm{vision}}) $$
然后使用视觉编码器将 Patch 序列编码为图片特征序列:
$$ \mathrm{\boldsymbol{Z}}_{\mathrm{vision}}=\mathrm{VisionEncoder}(\mathrm{\boldsymbol{P}}_{\mathrm{vision}}) $$
视觉编码器的特征维度往往和大模型不同,并且没有对齐。因此需要一个连接层,将视觉编码器特征映射对齐到文本特征。该连接层可以是单纯的 MLP:
$$ \mathrm{\boldsymbol{H}}_{\mathrm{vision}}=\mathrm{MLP}(\mathrm{\boldsymbol{Z}}_{\mathrm{vision}}) $$
特征整合
根据原始指令的排列顺序,连接得到最终的特征序列。例如如果原始指令为:
$$ \mathrm{\boldsymbol{X}}_{\mathrm{instruct}}=[\mathrm{\boldsymbol{X}}_{\mathrm{text}_1},\mathrm{\boldsymbol{X}}_{\mathrm{vision}},\mathrm{\boldsymbol{X}}_{\mathrm{text}_2}] $$
那么特征序列则连接为:
$$ \mathrm{\boldsymbol{H}}_{\mathrm{instruct}}=[\mathrm{\boldsymbol{H}}_{\mathrm{text}_1},\mathrm{\boldsymbol{H}}_{\mathrm{vision}},\mathrm{\boldsymbol{H}}_{\mathrm{text}_2}] $$
解码生成
得到了特征序列 $\mathrm{\boldsymbol{H}}_{\mathrm{instruct}}$ 后,接下来的生成流程就和标准大模型一样了。将特征序列输入大模型 Decoder,通过大模型解码算法预测得到下一个 Token,然后将新 Token 尾接到输入,进行自回归生成。
$$ P(y_1, y_2, ..., y_T | x) = \prod_{t=1}^T P(y_t | y_1, ..., y_{t-1}, x) $$
3 训练流程
视觉大模型的训练流程可能各有差异,下面介绍的是最常见和基础的一种。
构建大语言模型、视觉编码器
视觉语言模型通常不是从零启动构建的,而是首先预训练大模型和视觉编码器,而这一步可能是事先已经完成了的工作。
例如 LLaVA 使用的便是预训练的 Vicuna 作为大模型,预训练的 CLIP 作为视觉编码器,或是最近的 Intern-S1 使用预训练的 Qwen3 作为大模型,预训练的 InternViT 作为视觉编码器。
这个部分的训练就参照对应模型的训练,如果直接把权重拿过来用得话也无需关注太多,因此不做展开。
视觉语言模型预训练
从这里开始,大模型、视觉编码器和连接层已经组装为整体,开始整体的训练。
预训练阶段,视觉编码器与大模型的参数均冻结不参与训练,仅有连接层的 MLP 参数参与训练,用于训练连接层的多模态对齐能力。
此时的训练数据大多是一些简单的视觉问题,输入是图片和对图片的提问,输出是对图片的描述(Caption)。
视觉语言模型微调
在微调阶段,视觉编码器的参数保持冻结,连接层的 MLP 参数和大模型解码器参数参与训练,用于提升模型对于更复杂视觉问题的解决能力。
此时的训练数据就是更复杂的指令微调数据,输入是图片和相关的用户指令(Instruction),输出是对应的回答(Answer)。
4 其他模态
视觉语言模型的核心思路是将多种模态通过编码器映射到同一个特征空间,再由大模型进行解码生成,那么是不是任何其他模态均可以这样做呢?实际上是可以的,并且已经广泛验证。
无论是图片、视频还是音频,还是时序数据、图数据等等,只要设计合理的编码器能将其编码为特征向量,再与大模型解码器结合,就可以实现该模态的理解(当然实际中肯定是有各种难点的)。
例如 Qwen2.5-Omni,就是通过 Qwen2-Audio 的音频编码器编码音频,通过基于 ViT 的 Qwen2.5-VL 视觉编码器编码图片、视频,从而完成了对应模态的理解能力。
又如化学领域的一些模型例如 InstructMol,它通过基于图神经网络(GNN)的 MoleculeSTM 完成化学分子的编码,从而实现了对化学分子模态的理解能力。
5 源代码
为了更深入理解,我也对源代码进行了注释,梳理了模型的整个生成流程,可以参考学习。代码库如下:https://github.com/ChrisKimZHT/LLaVA.git
preview.py | 生成流程:
- 接受图片
https://llava-vl.github.io/static/images/view.jpg与提示词Describe this picture in detail. - 应用 ChatTemplate:
A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: <image>\nDescribe this picture in detail. ASSISTANT: - 读取图片内容与图片大小 image_sizes
List[Tuple[int, int]] mm_utils.process_images() | 预处理图片
- 将图片填充为正方形,以长边为基准,短边居中填充到长边长度,填充背景色是 CLIP 预定义好的平均颜色
CLIPImageProcessor.preprocess() | 使用视觉编码器的预处理模块处理图片
- 缩放、归一化等操作,得到
(channel, height, weight)的 Tensor
- 缩放、归一化等操作,得到
- 堆叠所有图片,得到
(batch_size, channel, height, weight)的 Tensor images_tensor
mm_utils.tokenizer_image_token() | Tokenize 提示词
- 先从
<image>处断开,然后分别每段 tokenize 获得 input_ids - 将 Tokenize 后的结果拼接在一起,中间插入特殊标记
IMAGE_TOKEN_INDEX,注意这里需要特判BOS - 得到
(batch_size, seq_len)的 Tensor input_ids
- 先从
LlavaLlamaForCausalLM.generate() | 传入 input_ids, images_tensor, image_sizes 开始生成
LlavaMetaForCausalLM.prepare_inputs_labels_for_multimodal() | 构建多模态 Token
LlavaMetaForCausalLM.encode_images() | 获得图片 Token
CLIPVisionTower.forward() | 视觉编码器编码图片
- CLIPVisionModel.forward() | CLIP 编码图片,获得 CLIP 每一层的 hidden state
(layer_count, patch_count + 1, clip_dimension) CLIPVisionTower.feature_select() | 根据多模态特征选择方式选择 hidden state
- 选择指定层数的 hidden state,默认为
-2(倒数第 2 层) - 选择 hidden state 中的特征,默认为
patch(仅图片块特征),还可选cls_patch(CLIP 的起始 Token 和图片块的特征) - 得到
(1, patch_count, clip_dimension)的特征
- 选择指定层数的 hidden state,默认为
- CLIPVisionModel.forward() | CLIP 编码图片,获得 CLIP 每一层的 hidden state
LlavaMetaModel.mm_projector() | 投影层对齐图片特征
- 投影层由
mm_projector_type配置,默认为 2 层 MLP,GeLU 激活 - 得到
(image_count, patch_count, llm_dimension)的特征
- 投影层由
- 将图片 Embedded(特征)和文本 Embedded 拼接到一起,得到
(batch_size, seq_length, hidden_size)的张量 inputs_embeds
- LlamaForCausalLM.generate() | 处理好多模态输入后,传入 inputs_embeds 调用 LLM 骨干解码生成,得到 output_ids
- tokenizer.batch_decode() | 解码 output_ids 得到模型输出
本文采用 CC BY-SA 4.0 许可,本文 Markdown 源码:Haotian-BiJi