机器学习 | GPT-2
GPT-2 (Generative Pre-trained Transformer 2): 是 OpenAI 发布的 GPT 系列大语言模型的第二代。它采用了纯解码器 (decoder only) 的结构,是一种自回归语言模型。
注意力机制是 GPT 的核心,前置文章:https://io.zouht.com/178.html
1 总体结构
1.1 回顾 Encoder-Decoder 结构
GPT-2 采用了 Decoder Only 的结构,在介绍它之前,不妨先看一下最原始的 Encoder-Decoder 结构。在 Attention Is All You Need 论文中介绍的便是 Encoder-Decoder 结构,最初用作机器翻译任务。它的结构图示如下:
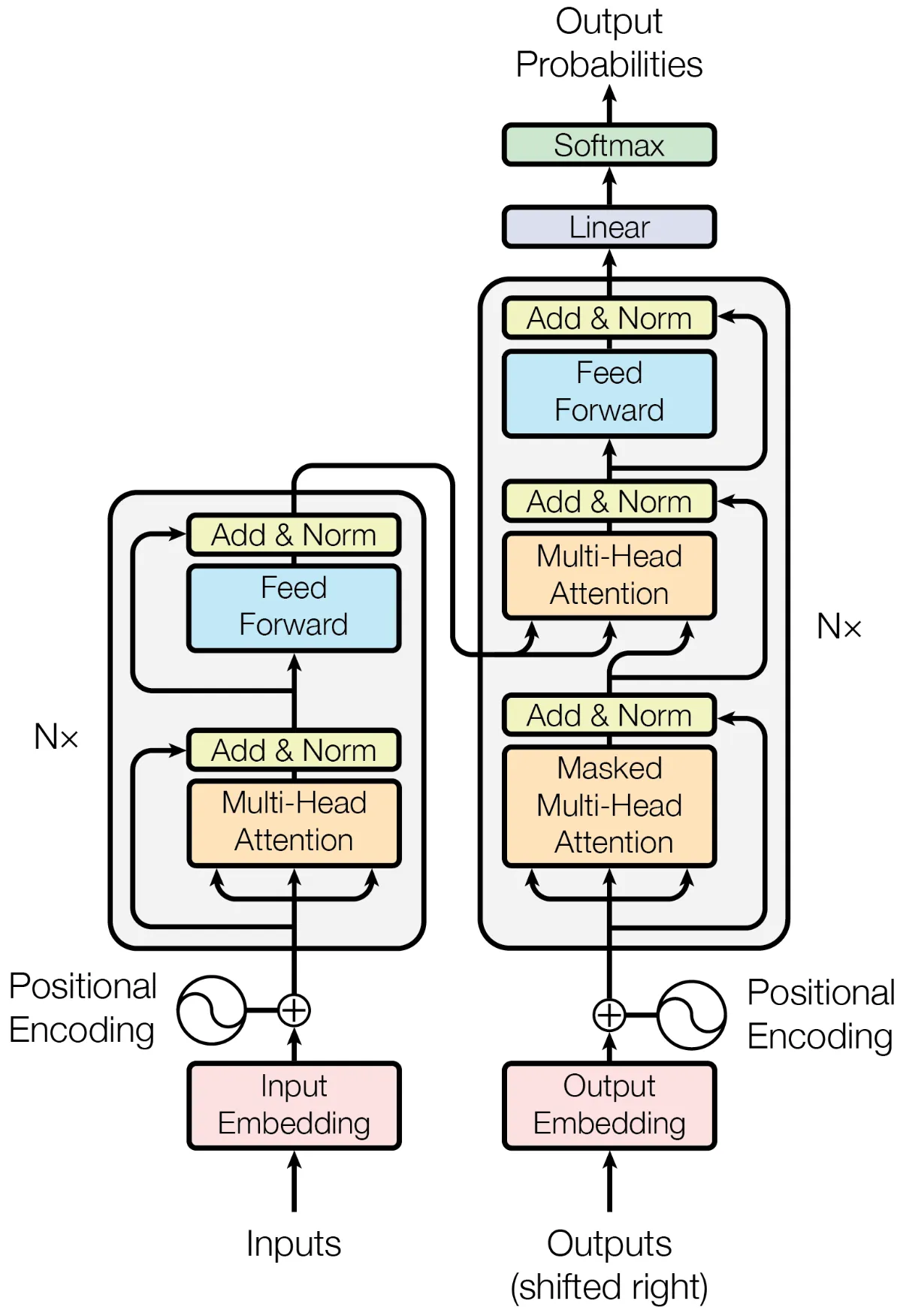
图片来源:Attention Is All You Need
要理解这个结构的意义,得结合它的应用——机器翻译。对于翻译任务,给出原语言的文本,第一步便是理解和提取原语言文本中蕴含的信息。然后借助提取得到的信息,生成目标语言的翻译。在生成目标语言的过程中,也要注意前文与后文的关联,遵循目标语言潜在的规则。
Encoder 模块(上图左侧部分)便是负责提取源语言内涵的信息,通过一层又一层的基于多头注意力机制的 Encoder 块,理解原文本中 Token 间的关联,提取源文本中的信息,最后输出一个向量。下面是 Encoder 的注意力可视化,可见 Encoder 只在源文本范围进行注意力计算。
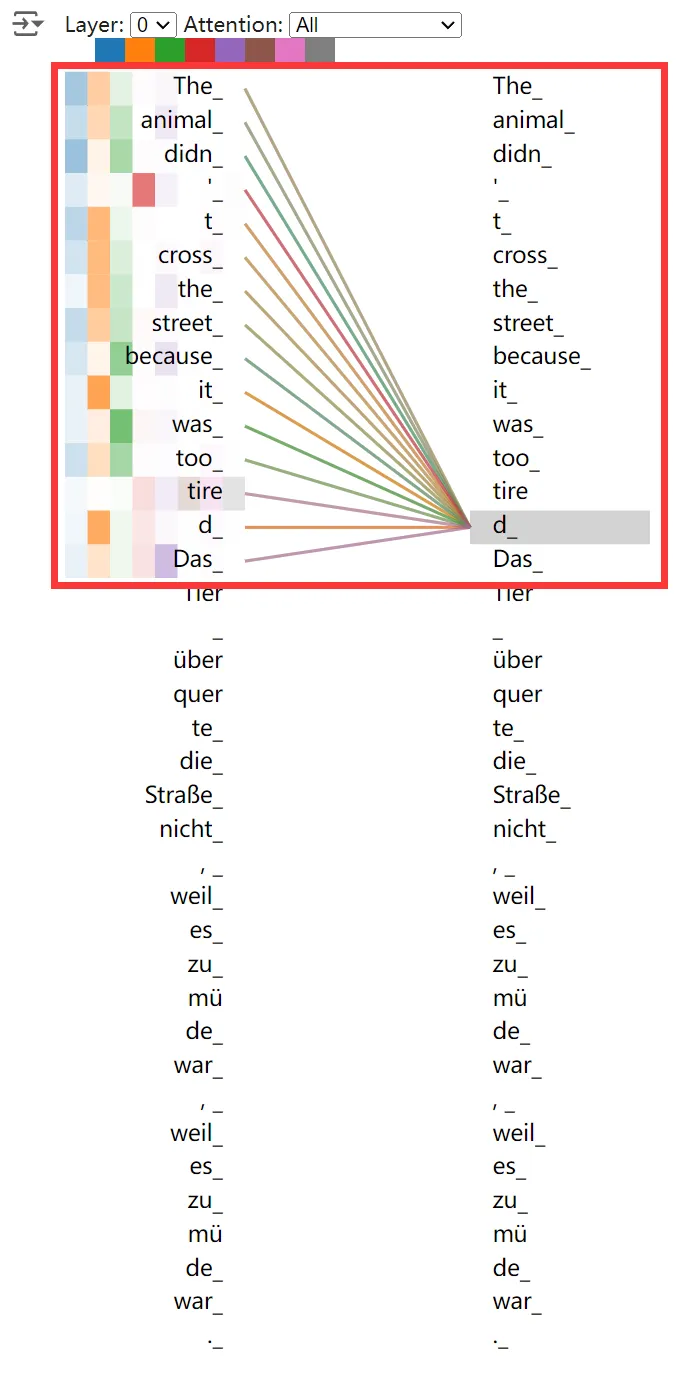
图片来源:Tensor2Tensor Intro
Decoder 模块(上图右侧部分)便是负责依据提取信息生成目标语言,接受从 Encoder 模块传入的向量,同时结合当前已经生成的目标语言的 Token 序列,生成下一个 Token。需要注意的是,Decoder 模块有两种注意力:encoder-decode 注意力和 masked 注意力。对于 encoder-decode 注意力,就是提取源语言和目标语言之间的关联。对于 masked 注意力,它通过遮罩仅允许当前位置利用之前的信息进行预测,可以理解为后侧位置的信息会“泄露答案”给当前位置,这是不利于训练的。
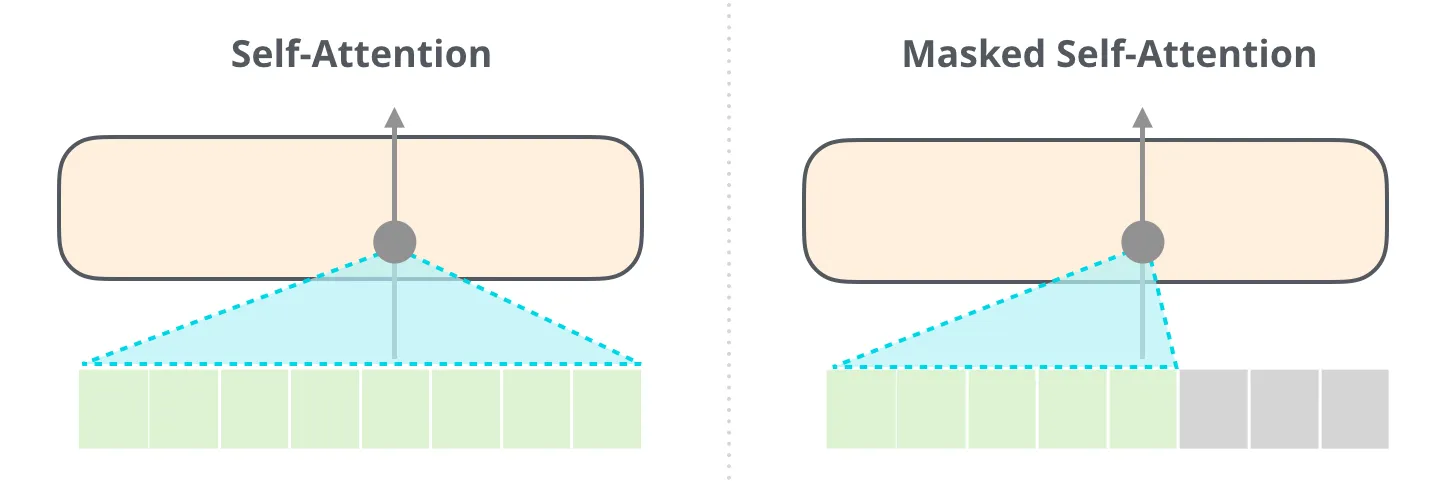
图片来源:https://jalammar.github.io/illustrated-gpt2/,采用:CC BY-NC-SA 4.0
下面是 Decoder 模块的注意力可视化,可以看见 Decoder 输出的 Token 能够利用源语言 Token 序列的信息,这便是 encoder-decode 注意力实现的。同时输出的目标语言 Token 只能利用之前输出的 Token(彩色连线),而不能利用后面的 Token(灰色连线),这便是 masked 注意力实现的。
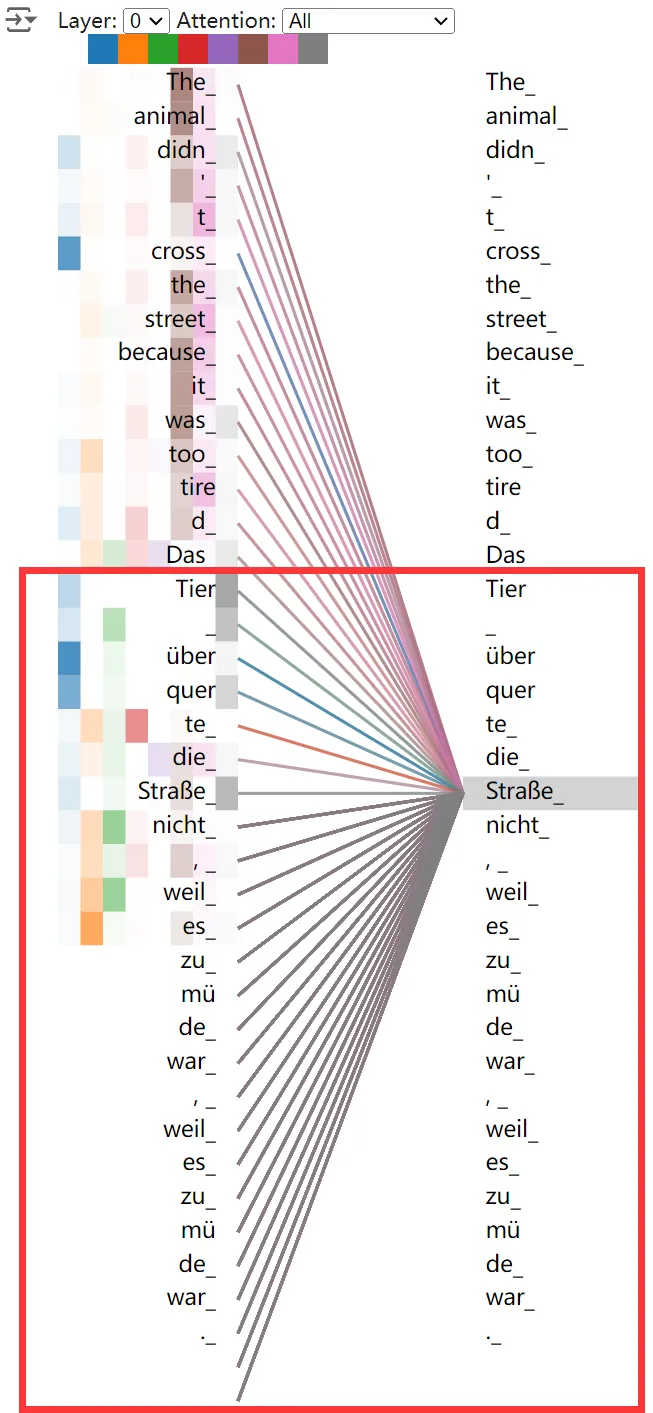
图片来源:Tensor2Tensor Intro
了解了 Encoder-Decoder 结构后,可以发现该结构和机器翻译任务极为契合,但这也说明这种结构可能不适合其他任务。
1.2 Decoder Only 结构
GPT-2 采用了一种新的结构,在整个模型中只存在 Decoder 模块,称为 Decoder Only 结构。
由于没有 Encoder,Decoder 模块的 encoder-decode 注意力就没有意义了,因此它也被移除了。可以回看本文 Encoder-Decoder 结构的图示,其中把 Decoder 的 Multi-Head Attention 和它的 Add&Norm 删掉,便是 GPT-2 的 Decoder 结构了(其实也可以看作把 Encoder 的 Multi-Head Attention 换成 Masked Multi-Head Attention).
以下便是 GPT-2 的总体结构了:
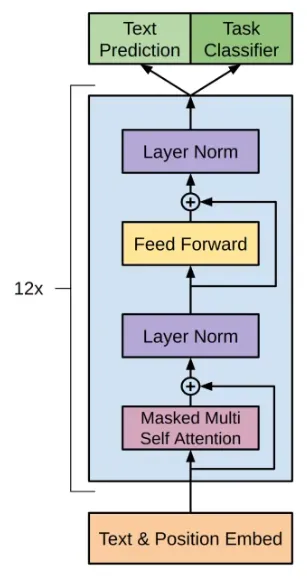
2 结构细节
通过对比 GPT-2 的源码和上面的结构图,可以更加深入理解它的模型结构。
https://github.com/openai/gpt-2/blob/master/src/model.py
2.1 位置编码
GPT-2 采用了一种非常简单的绝对位置编码方式,即直接从 $0$ 开始顺序给每个 Token 编号。
def expand_tile(value, size):
"""Add a new axis of given size."""
value = tf.convert_to_tensor(value, name='value')
ndims = value.shape.ndims
return tf.tile(tf.expand_dims(value, axis=0), [size] + [1]*ndims)
def positions_for(tokens, past_length):
batch_size = tf.shape(tokens)[0]
nsteps = tf.shape(tokens)[1]
return expand_tile(past_length + tf.range(nsteps), batch_size)用一个示例来运行,可以看见位置编码的结果如下:
tokens = tf.constant([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]])
print(positions_for(tokens, 0))
# tf.Tensor(
# [[0 1 2 3 4]
# [0 1 2 3 4]
# [0 1 2 3 4]], shape=(3, 5), dtype=int32)
print(positions_for(tokens, 2))
# tf.Tensor(
# [[2 3 4 5 6]
# [2 3 4 5 6]
# [2 3 4 5 6]], shape=(3, 5), dtype=int32)2.2 Text Embed & Position Embed
GPT-2 使用两个可训练矩阵来做 Text Embed 和 Position Embed,模型将会自学习文本 (Token) 和位置编码嵌入为向量的方式:
wpe = tf.get_variable('wpe', [hparams.n_ctx, hparams.n_embd], initializer=tf.random_normal_initializer(stddev=0.01))
wte = tf.get_variable('wte', [hparams.n_vocab, hparams.n_embd], initializer=tf.random_normal_initializer(stddev=0.02))最终的嵌入向量由词嵌入向量和位置嵌入向量相加得到:
past_length = 0 if past is None else tf.shape(past)[-2]
h = tf.gather(wte, X) + tf.gather(wpe, positions_for(X, past_length))2.3 Decoder
下面便是 GPT-2 的核心,即 Decoder 块的实现:
def block(x, scope, *, past, hparams):
with tf.variable_scope(scope):
nx = x.shape[-1].value
a, present = attn(norm(x, 'ln_1'), 'attn', nx, past=past, hparams=hparams)
x = x + a
m = mlp(norm(x, 'ln_2'), 'mlp', nx*4, hparams=hparams)
x = x + m
return x, present和下图进行对比,可以发现 Attention、MLP 和残差连接都能对应上。
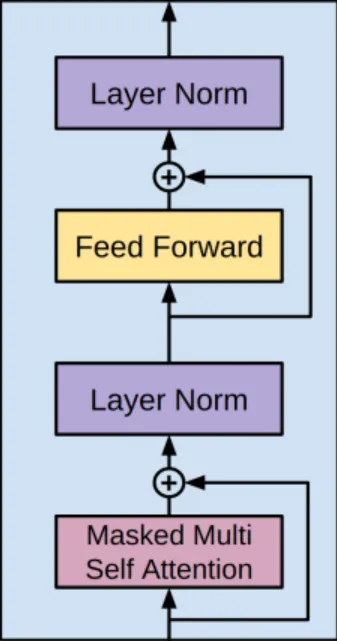
不过发现 Layer Norm 的位置似乎不一样,在代码实现中,Layer Norm 是在 Attention 和 MLP 之前的。
Decoder 块要堆叠多层,对应的便是代码的这个循环:
for layer, past in enumerate(pasts):
h, present = block(h, 'h%d' % layer, past=past, hparams=hparams)
presents.append(present)2.4 输出
最后一个 Decoder 的输出向量便是预测下一个 Token 需要用到的信息,首先把它还原成二维张量:
h_flat = tf.reshape(h, [batch*sequence, hparams.n_embd])接下来用 Text Embed 矩阵把它从 Embed 空间还原到 Token 空间,输出一个预测概率的张量:
logits = tf.matmul(h_flat, wte, transpose_b=True)
logits = tf.reshape(logits, [batch, sequence, hparams.n_vocab])其中每一行代表一个单词的预测,即模型预测每个词是词汇表中每个其他词的概率。
2.5 超参数
def default_hparams():
return HParams(
n_vocab=0,
n_ctx=1024,
n_embd=768,
n_head=12,
n_layer=12,
)3 运行流程
3.1 一次推理
首先需要输入一段 Token 序列,可以是一段待补全的句子如 robot must obey ...,如果想要从零生成,也可以直接输入一个特别的起始 Token <s> 来开始运行。获得输入的 Token 序列后,显然它是不满足 Context 长度的,因此在序列后加上 <pad> 填充到目标长度。该 Token 序列经过词汇表编码,送入模型进行推理,最后会得到一个预测结果的概率分布,下面就需要依据概率分布选取预测的结果了。
3.2 选取结果
Top-k 和 temperature 是两种在 GPT 中常用的策略,用于控制模型生成文本的随机性和多样性。这两种策略在模型生成文本时,会影响模型选择下一个词的方式。
Top-k
在生成模型中,每个词的生成都是基于一个概率分布的。模型会为每个可能的下一个词分配一个概率,然后从这个分布中抽取一个词。抽取过程如下:
- 模型会计算出每个可能的下一个词的概率。
- 然后,模型会选择概率最高的 k 个词。
- 最后,模型会从这 k 个词中随机抽取一个。
Temperature
Temperature 抽样的公式可以用 softmax 函数表示。假设模型的原始输出是一个向量 $z$,其中 $z_i$ 是第 i 个词的原始输出。那么,经过 temperature 抽样后,第 $i$ 个词被选中的概率 $p_i$ 可以用下面的公式计算:
$$ p_i = \frac{e^{z_i / T}}{\sum_j e^{z_j / T}} $$
其中,$T$ 是 temperature 参数,$sum_j$ 是对所有可能的词求和。这个公式说明:
- 当 $T$ 越小,高概率的词会变得更有可能被抽到,低概率的词会变得更不可能被抽到,模型更加固定。
- 当 $T$ 越大,高概率和低概率的词之间的差距会变得更小,模型生成的文本会更加随机和多样。
3.3 连续推理
GPT-2 是一种自回归语言模型,它预测下一个 Token 时需要基于它以前的 Token 以及当前的输入,即:
$$ h_i=\mathrm{LM}_{\phi}(z_i,h_{<i}) $$
因此,它的运行过程实际上是一个循环的过程。经过 3.1 的一次推理流程后,用 3.2 的方式选取预测的 Token,然后将预测 Token 尾接到输入,再进行推理。循环直到达到需要的长度为止。
本文采用 CC BY-SA 4.0 许可,本文 Markdown 源码:Haotian-BiJi