机器学习 | P⁎-Tuning
P*-tuning:一类模型微调方法,微调思想基于 Prompt 技术,不改变模型的主体参数,而是专注于优化一个小型的、任务特定的 Prompt,这个 Prompt 被设计来激活和引导模型生成特定类型的回答。
本篇文章为论文笔记,图片截取自原论文。
1 Prompting
在 P*-tuning 这一系列微调方法出现之前,Prompting 是一个有效的模型微调方法。它主要有提示学习 (prompt-based learning) 和语境学习 (in-context learning) 两种形式。
1.1 提示学习
提示学习的流程非常直观,可解释性很强。下面直接用例子来解释,如果要使用大语言模型做评论情感分类问题:
- 首先设计提示模板:
<X>的情感是<Y>,<X>用来插入具体评论,<Y>留给模型做预测。 - 然后需要设计答案空间,例如对于这个问题,
<Y>的取值可以是积极、中立、消极. - 接下来将需要推理的数据组合到模板内:
这个电影太烂了的情感是<Y> - 最后交给模型进行预测,对于这个例子,期望模型预测输出为
消极,完成了评论的分类。
1.2 语境学习
语境学习的流程也很直观,直接用一样的评论情感分类的例子:
首先需要设计一些示例:
- 这个电影让我昏昏欲睡。\n消极
- 这部电影有好有坏,总体算合格,\n中立
- 这部电影非常好看。\n积极
- 然后需要设计答案空间,例如对于这个问题可以是
积极、中立、消极. 然后将需要推理的数据和示例组合:
- 这个电影让我昏昏欲睡。\n消极
- 这部电影有好有坏,总体算合格,\n中立
- 这部电影非常好看。\n积极
- 这部电影看得非常过瘾,我非常喜欢。\n
- 将组合后的数据交给模型预测,对于这个例子,期望模型预测输出为
积极,完成了评论的分类。
2 Prefix-tuning
对于 Prompting 方法,一个问题就是设计的 Prompt 都是离散的 Token,常常是人工进行设计的,无法使用优化器进行自动训练。Prefix-Tuning 旨在将显式的离散的 Prompt 设计改为隐式的连续的 Prefix 优化,让微调流程可以通过优化器反向传播自动完成。
2.1 方法
自回归结构
对于自回归语言模型,它计算当前输入的激活向量时需要基于它以前的激活向量以及当前的输入向量,即:
$$ h_i=\mathrm{LM}_{\phi}(z_i,h_{<i}) $$
这个公式实际上是紧凑的写法,其中 $h_i$ 实际上是模型每一层的激活向量拼接而成的整个激活向量,即 $h_i=[h_i^{(1)},h_i^{(2)},\cdots,h_i^{(n)}]$,同时上面的 $\mathrm{LM}(\cdot)$ 实际上代表了包含多个层的整个模型。
然后接下来通过最后一层的激活向量 $h_i^{(n)}$,预测下一个 Token:
$$ p_{\phi}(z_{i+1}|h_{\leq i})=\mathrm{softmax}(W_{\phi}h_i^{(n)}) $$
其中,$W_{\phi}$ 的作用是将 $h_i^{(n)}$ 映射为当前词汇表的一个概率分布,从而确定下一个 Token。
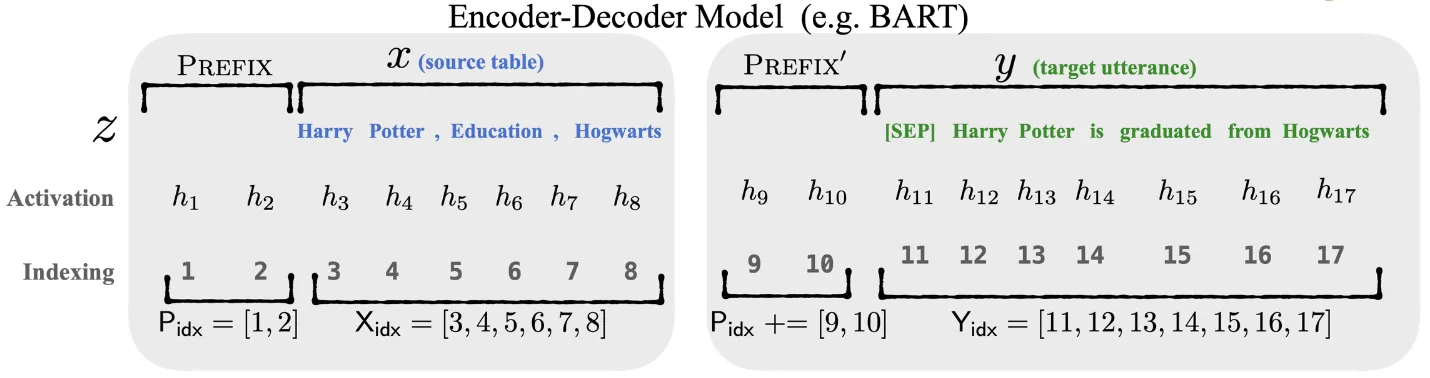
Prefix-tuning 在自回归模型中的每一层前添加前缀,如下图所示:

记 $P_{\mathrm{idx}}$ 为选择的前缀的编号,那么 $|P_{\mathrm{idx}}|$ 便可以代表选择的前缀长度(例如上图 $|P_{\mathrm{idx}}|=2$),参数量为 $|P_{\mathrm{idx}}|\times \dim(h_i)$. 加上前缀后,激活向量的计算公式变为:
$$ h_i= \begin{cases} P_{\theta}[i,:],&\text{if}\;i\in P_{\mathrm{idx}},\\ h_i=\mathrm{LM}_{\phi}(z_i,h_{<i}),&\text{otherwise}. \end{cases} $$
简单来说就是每一层长度为 $|P_{\mathrm{idx}}|$ 的前缀就不是循环计算得出的,而是完全自由的可训练参数了,前缀后面的部分则保持计算方式不变。
编码器-解码器结构
在编码器-解码器结构中,编码器是双向的,解码器则是自回归模型。Prefix-tuning 在编码器-解码器结构的编码器、解码器前均添加前缀,如下图所示。
2.2 训练
对于全量微调训练,用公式表示为:
$$ \max_{\phi}\sum_{i\in \text{Y}_{\mathrm{idx}}}\log p_{\phi}(z_i|h_{<i}) $$
Prefix-tuning 的训练公式则为:
$$ \max_{\theta}\sum_{i\in \text{Y}_{\mathrm{idx}}}\log p_{\phi,\theta}(z_i|h_{<i}) $$
可以发现变化就是训练参数变了,$\phi$ 作为预训练参数被固定下来,而训练参数变成了 $\theta$.
另外,作者认为直接优化 $P_\theta$ 是不稳定的,并且会降低准确率。因此使用将 $P_{\theta}$ 重参数化为一个更小的矩阵 $P_{\theta}'$ 和一个大 MLP 层 $\text{MLP}_{\theta}$,它们的关系是:
$$ P_{\theta}[i,:]=\text{MLP}_\theta(P'_{\theta}[i,:]) $$
从公式可以看出,$P_\theta$ 和 $P_\theta'$ 的行数应当相当,区别仅为 $P_{\theta}'$ 的列数更小。
另外,当训练完成后,就可以通过 $P_\theta'$ 和 $\text{MLP}_{\theta}$ 生成最终的 $P_\theta$,然后 $P_\theta'$ 和 $\text{MLP}_{\theta}$ 就没有用了,可以丢弃。
3 Prompt Tuning
Prompt Tuning 可以看作 Prefix-tuning 的进一步简化,实际上它可以看作把 Prompting 方法的不可微分的离散提示改为了可优化的连续提示。
它与 Prefix-tuning 的核心区别就是:Prefix-tuning 对每一层都添加可训练前缀参数,而 Prompt Tuning 只在输入前额外训练参数。
它的一大好处就是将 LLM 视为了一个黑盒,即使在无法修改 LLM 结构的条件下也能完成微调。它还有一大好处是,由于它只对输入添加前缀,这就可以实现多个不同的下游任务可以放在同一 Batch 中交给模型处理,并行程度更高。
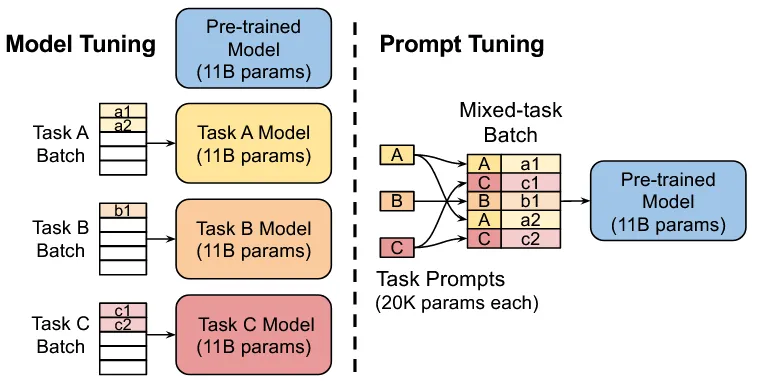
3.1 方法
Prompt Tuning 的思想非常简单:离散 Prompt Token 经过 Embedding 后就会变为连续的 Embed 向量,那么在 Embed 操作后的 Embed 向量前拼接前缀矩阵,就是连续可微的了。
根据这个流程,对于长度为 $n$ 的一串输入 Token $\{x_1,x_2,\cdots,x_n\}$,经过 Embed 操作后会得到一串向量 $\{e_1,e_2,\cdots,e_n\}$,记作 $E\in\mathbb{R}^{n\times h}$,其中 $h$ 为嵌入维度。对于要添加的前缀矩阵 $P$,如果选择前缀长度为 $m$,则它的大小为 $P\in\mathbb{R}^{m\times h}$.
接下来,在原始的嵌入矩阵前拼接上前缀矩阵,就得到了模型的输入 $[P;E]\in\mathbb{R}^{(n+m)\times h}$,该输入正常流过模型后,进行反向传播更新 $P$ 即可。
综上,Prompt Tuning 的训练参数量为 $m\times h$,与选取的前缀长度和模型的嵌入维度有关。
3.2 初始值
$P$ 的初始值如何选取是值得注意的,最简单的方法便是随机初始化。
但考虑到 $P$ 的含义实际上是经过嵌入操作后的嵌入矩阵,那么参考 Token 词表会更好,即从 Token 词表的 Embedding 中挑选向量作为初始值。
另外,如果该微调任务是一个分类任务,还可以从答案空间(参考第 1 节)中挑选答案对应的 Embedding 作为初始值。
4 P-tuning
对于上文提到的 Prefix-tuning 和 Prompt Tuning,它们都是针对于自然语言生成 (NLG) 任务的,而本节的 P-tuning 是针对于自然语言理解 (NLU) 任务的,这是它们的本质区别。
自然语言理解任务可以是语义分析、情感分析、主题识别、意图识别等。例如要求给一段电影评论做情感分类,这便是一个自然语言理解问题。
4.1 方法
回顾第 1.1 节的提示学习方法,首先要设计提示模板。提示模板的一般化的格式表示为:
$$ \text{<开头提示><X><中间提示><Y><结尾提示>} $$
例如,电影评论<X>的情感是<Y>的 这个提示模板便是符合上面这个格式的。
P-tuning 的思想实际上和 Prompt Tuning 几乎一致。回顾第 3.1 节,它在 Embedding 后的 Embed 向量前拼接前缀矩阵作为 Prompt,然后使用优化器进行训练:
$$ [P;X] $$
P-tuning 的区别只是拼接位置不同,它是按照提示模板的格式进行拼接,即 Prompt 会在 Embed 向量前、后和中间插入:
$$ [P_1;X;P_2;Y;P_3] $$
另外还有一点就是,P-tuning 加入的 Prompt 矩阵实际上经过了重参数化,思想和第 2.2 节的重参数化类似,论文里称为“提示编码器 (Prompt Encoder)”。论文中选用 MLPs 或 LSTM 网络进行重参数化。
4.2 优化
P-tuning v2 在 P-tuning 基础上进行了进一步研究,优化了性能。它实际上把 Prefix-tuning (第 2 节) 的思想融合到了 P-Tuning 里,即 Prefix-tuning 对每一层都添加可训练 Prompt 参数,而 P-tuning 只在输入前额外的 Prompt 训练参数。
P-tuning 和 P-tuning v2 的结构对比如下图所示,可见 v2 的每一层都有可训练的 Prompt 参数:
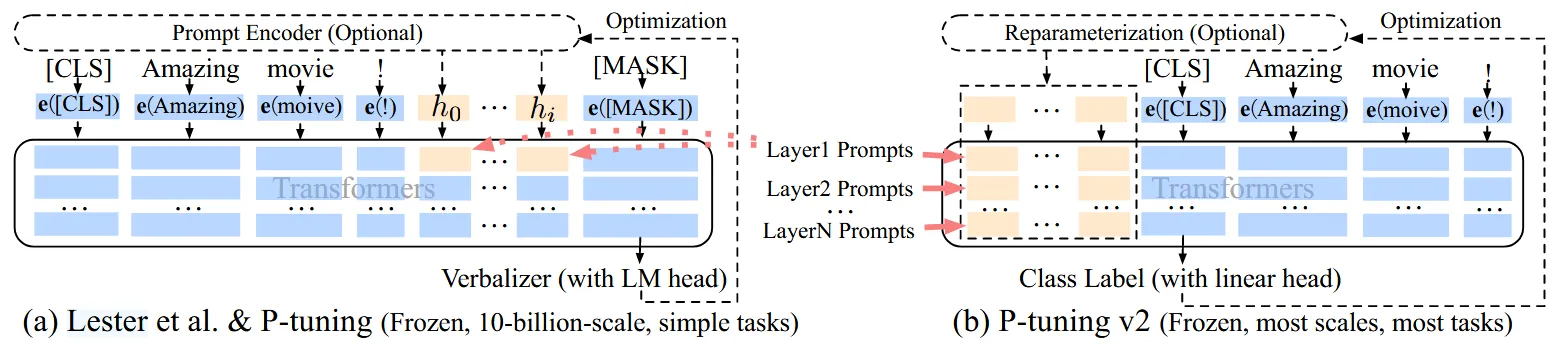
另外,P-tuning v2 提出 v1 里做的重参数化并不一定能提升性能。使用 MLPs 或 LSTM 网络重参数化 Prompt 矩阵产生的效果与具体的任务相关,不同任务适合的方法不同,有时添加重参数化甚至会降低性能。
此外,P-tuning v2 提出 Prompt 的长度对效果有重要影响,简单的分类问题倾向使用 20 以下的 Prompt 长度,复杂的使用约 100 的长度。
最后,P-tuning v2 提出使用语言模型的 Verbalizer 作为分类头并不一定合适,将其改为直接使用线性分类头更加合适。
本文采用 CC BY-SA 4.0 许可,本文 Markdown 源码:Haotian-BiJi