机器学习 | 支持向量机
支持向量机 (Support Vector Machine, SVM):支持向量机在高维或无限维空间中构造超平面或超平面集合,其可以用于分类、回归或其他任务。直观来说,分类边界距离最近的训练资料点越远越好,因为这样可以缩小分类器的泛化误差。
1. 定义
更正式地来说,支持向量机在高维或无限维空间中构造超平面或超平面集合,其可以用于分类、回归或其他任务。直观来说,分类边界距离最近的训练资料点越远越好,因为这样可以缩小分类器的泛化误差。(来源:维基百科,使用 CC BY-SA 3.0 协议)
对于二维二分类问题如下:
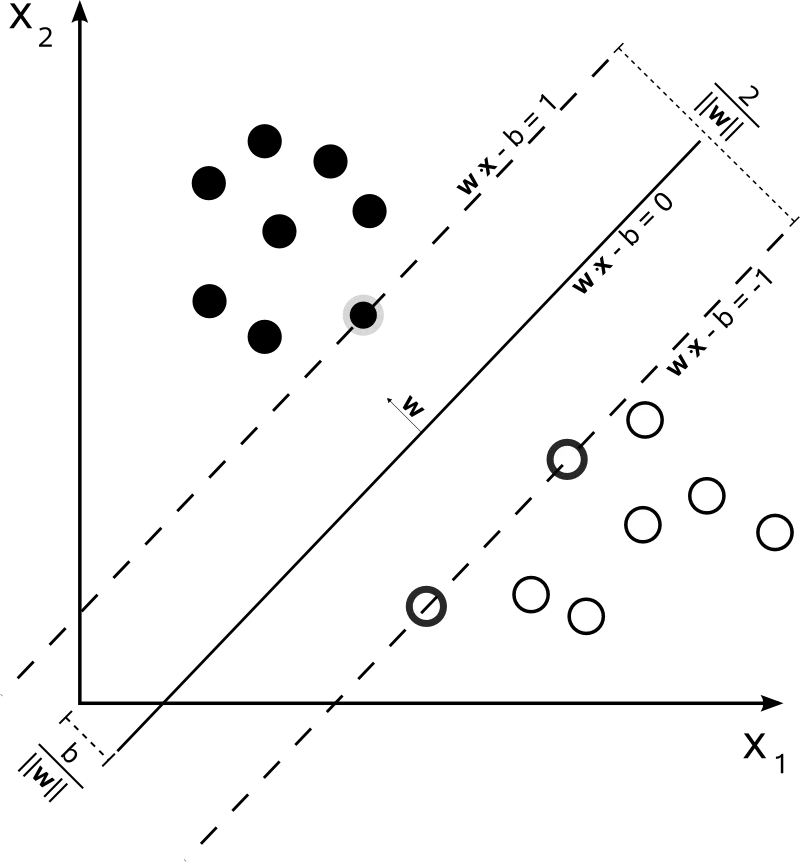
(来源:维基百科,使用 CC BY-SA 3.0 协议)
当我们来对两种样本人工分类的时候,一定是想找到间隔最宽的一个空隙划开,因为我们感觉这样的分类效果最好。
支持向量机和人的思维一致,就是要找到一个分类超平面 $\boldsymbol{w}\cdot\boldsymbol{x}-b=0$,并且希望该超平面支持向量的间隔越大越好,因为这样可以减小在测试集上的泛化误差。
支持向量是训练数据集中最靠近分类超平面的点。
2. 线性 SVM
2.1 硬间隔
2.1.1 间隔的定义
SVM 的核心就是间隔越大越好,那么我们首先要找到间隔的数学表达。
平面中点 $(x_0,y_0)$ 到直线的 $ax+by+c=0$ 距离公式:
$$ d=\frac{|ax_0+by_0+c|}{\sqrt{a^2+b^2}} \tag{a.1} $$
有些资料向量相乘写成 $\boldsymbol{w}\cdot\boldsymbol{x}$,有些资料写成 $\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}$,二者实际是一样的。因为前者是点乘(内积),后者是叉乘(外积)。
将上式推广到多维空间中一样成立。对于超平面 $\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b=0$,点 $\boldsymbol{x}$ 到其的距离为:
$$ d=\frac{\lvert\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b\rvert}{\lVert\boldsymbol{w}\rVert} \tag{a.2} $$
$\lVert\boldsymbol{x}\rVert$ 为 $\boldsymbol{x}$ 的二范数(下标 2 可省略),其定义是:$\lVert\boldsymbol{x}\rVert_2=\sqrt{\sum_{i=1}^n x_i^2}$
我们将 $\pm1$ 作为每个样本点的类别标签,如果样本可以线性可分,那么一定存在分类超平面满足:
$$ \begin{cases} \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b>0,&y_i=1\\ \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b<0,&y_i=-1 \end{cases} \tag{a.3} $$
这个条件实际上非常弱,它相当于只规定了分类超平面能把两种样本点隔开,没有任何对间隔的限制。
为了引入间隔,我们假设支持向量到分类超平面的距离为 $d$,那么我们要求分类超平面:
$$ \begin{cases} \text{if }y_i=1,&\text{then }\frac{\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b}{\lVert\boldsymbol{w}\rVert}\geq d\\ \text{if }y_i=-1,&\text{then }\frac{\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b}{\lVert\boldsymbol{w}\rVert}\leq -d \end{cases} \tag{a.4} $$
这样表达式中终于包含了间隔。接下来,我们对上式两边除以 $d$:
$$ \begin{cases} \text{if }y_i=1,&\text{then }\frac{\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b}{\lVert\boldsymbol{w}\rVert d}\geq 1\\ \text{if }y_i=-1,&\text{then }\frac{\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b}{\lVert\boldsymbol{w}\rVert d}\leq -1 \end{cases} \tag{a.5} $$
由于 $\lVert\boldsymbol{w}\rVert$ 和 $d$ 都是标量,因此除以分母相当于对该超平面进行缩放,实际上超平面是没有变化的。
就像 $2x+4y=0$ 缩放为 $x+2y=0$,两个式子表示的仍然是同一条直线。
因此为了式子简单,我们直接忽略掉缩放的值:
$$ \begin{cases} \text{if }y_i=1,&\text{then }\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b\geq 1\\ \text{if }y_i=-1,&\text{then }\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b\leq -1 \end{cases} \tag{a.6} $$
对于支持向量 $\boldsymbol{x}_i$,其满足:
$$ \lvert\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b\rvert=1 \tag{a.7} $$
那么支持向量与分类超平面的距离为:
$$ d=\frac{\lvert\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b\rvert}{\lVert\boldsymbol{w}\rVert}=\frac{1}{\lVert\boldsymbol{w}\rVert} \tag{a.8} $$
由于间隔有两侧,那么间隔的距离为:
$$ d=\frac{2}{\lVert\boldsymbol{w}\rVert} \tag{a.9} $$
2.1.2 待求解的问题
获得了间隔的表达式,支持向量机要求解的问题就可以用形式化的语言表达:
$$ \begin{align} &\max_{\boldsymbol{w},b}\frac{2}{\lVert\boldsymbol{w}\rVert}\\ &s.t.\;y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)\geq1 \end{align} \tag{b.1} $$
这里第二行公式把 $y_i$ 乘到左边去了,是为了表达式的简洁。实际上这一行表达的含义与式 $\text{(a.6)}$ 是一模一样的。
我们习惯求最小化问题,因此将以上问题分子分母颠倒,等价转换为:
$$ \begin{align} &\min_{\boldsymbol{w},b}\frac{1}{2}\lVert\boldsymbol{w}\rVert^2\\ &s.t.\;y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)\geq1 \end{align} \tag{b.2} $$
其中,加平方是为了求导时正好能把前面的 $1/2$ 消去。
2.1.3 前置知识
可以先看下一节求解的过程,过程中遇到了对应的方法后再看这一节。
2.1.3.1 拉格朗日乘子法
对于不等式约束优化问题:
$$ \begin{align} &\min_xf(x)\\ &\begin{aligned} s.t.\;&h_i(x)=0,\;i = 1,2,...,m\\ &g_j(x)<0,\;j = 1,2,...,n \end{aligned} \end{align} $$
转化为其对应的无约束的拉格朗日函数:
$$ L(x,\boldsymbol\alpha,\boldsymbol\beta)=f(x)+\sum_{i=1}^m\alpha_i h_i(x) +\sum_{j=1}^n\beta_jg_j(x) $$
要满足 KKT 条件:
$$ \begin{align} \frac{\partial L(x,\boldsymbol\alpha,\boldsymbol\beta)}{\partial x}&= 0\tag{1}\\ \beta_jg_j(x) &= 0 , \ j=1,2,...,n\tag{2}\\ h_i(x)&= 0 , \ i=1,2,...,m\tag{3}\\ g_j(x) &\le 0 , \ j=1,2,...,n\tag{4}\\ \beta_j &\ge 0 , \ j=1,2,...,n\tag{5}\\ \end{align} $$
其中:
- 拉格朗日取得可行解的必要条件
- 松弛互补条件
- 初始的约束条件
- 初始的约束条件
- 不等式约束的拉格朗日乘子需满足的条件
2.1.3.2 拉格朗日对偶
对于原问题:
$$ p^*=\min_x\max_{\alpha,\beta;\beta_i\geq0}L(x,\alpha,\beta) $$
它的对偶问题为:
$$ d^*=\max_{\alpha,\beta;\beta_i\geq0}\min_x L(x,\alpha,\beta) $$
定义以下式子:
$$ \begin{align} f(\alpha,\beta)&=\min_x L(x,\alpha,\beta)\\ d^*&=\max_{\alpha,\beta;\beta_i\geq0}f(\alpha,\beta)=\max_{\alpha,\beta;\beta_i\geq0}\min_x L(x,\alpha,\beta)\\ g(x)&=\max_{\alpha,\beta;\beta_i\geq0} L(x,\alpha,\beta)\\ p^*&=\min_x g(x)=\min_x\max_{\alpha,\beta;\beta_i\geq0}L(x,\alpha,\beta)\\ \end{align} $$
我们可以写出如下不等式:
$$ f(\alpha,\beta)=\min_x L(x,\alpha,\beta)\leq L(x,\alpha,\beta)\leq\max_{\alpha,\beta;\beta_i\geq0} L(x,\alpha,\beta)=g(x) $$
再进一步转换到 $d^*$ 与 $p^*$ 上:
$$ d^*=\max_{\alpha,\beta;\beta_i\geq0}f(\alpha,\beta)\leq\min_x g(x)=p^* $$
综上,我们可以得到原问题 $p^*$ 和对偶问题 $d^*$ 的最优解的关系:
$$ d^*\leq p^* $$
2.1.3.3 SMO 算法
SMO (Sequential Minimal Optimization) 算法的基本步骤:
- 选取一对需要更新的变量 $\alpha_i$ 与 $\alpha_j$
- 固定 $\alpha_i$ 与 $\alpha_j$ 以外的参数,求解出更新后的 $\alpha_i$ 与 $\alpha_j$
一直循环以上两个步骤,直到收敛。
对于选取的 $\alpha_i$ 与 $\alpha_j$,可以使用随机选取的方法,但是该方法收敛速度较慢。更优的方法是选取最不满足 KKT 条件的参数,这样更新时收敛速度会更快。
2.1.4 求解支持向量机
2.1.4.1 问题转换
由拉格朗日乘子法,我们列出拉格朗日函数:
$$ L(\boldsymbol{w},b,\boldsymbol{\alpha})=\frac{1}{2}\lVert\boldsymbol{w}\rVert^2+\sum_{i=1}^m \alpha_i(1-y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)) $$
其中 $\alpha_i\geq0$,为拉格朗日乘子;$m$ 为样本点的数量。
我们知道,$1-\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b\leq0$,因此式子后半段的求和项一定 $\leq0$,那么 $L(\boldsymbol{w},b,\boldsymbol{\alpha})$ 的最大值为 $\frac{1}{2}\lVert\boldsymbol{w}\rVert^2$ 即原问题:
$$ \max_{\boldsymbol{\alpha}}L(\boldsymbol{w},b,\boldsymbol{\alpha})=\frac{1}{2}\lVert\boldsymbol{w}\rVert^2 $$
我们要求的是原问题的最小值,因此问题转换为:
$$ \min_{\boldsymbol{w},b}\max_{\boldsymbol{\alpha}}L(\boldsymbol{w},b,\boldsymbol{\alpha}) $$
该问题不好求解,因此使用拉格朗日对偶法转换为对偶问题,我们求出对偶问题的最大值,便是原问题的下界:
$$ \max_{\boldsymbol{\alpha}}\min_{\boldsymbol{w},b}L(\boldsymbol{w},b,\boldsymbol{\alpha}) $$
2.1.4.2 求解问题
第一步,求解内层问题:
$$ \min_{\boldsymbol{w},b}L(\boldsymbol{w},b,\boldsymbol{\alpha})=\min_{\boldsymbol{w},b}\frac{1}{2}\lVert\boldsymbol{w}\rVert^2+\sum_{i=1}^m \alpha_i(1-y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)) \tag{e.1} $$
首先对 $\boldsymbol{w}$ 与 $b$ 求偏导,并算出偏导为 $0$ 时的解:
$$ \begin{align} &\begin{cases} \displaystyle{\frac{\partial L(\boldsymbol{w},b,\boldsymbol{\alpha})}{\partial\boldsymbol{w}}=\boldsymbol{w}-\sum_{i=1}^m \alpha_i y_i\boldsymbol{x}_i=0}\\ \displaystyle{\frac{\partial L(\boldsymbol{w},b,\boldsymbol{\alpha})}{\partial b}=\sum_{i=1}^m \alpha_i y_i=0} \end{cases}\\ \Rightarrow &\begin{cases} \displaystyle{\boldsymbol{w}=\sum_{i=1}^m \alpha_i y_i \boldsymbol{x}_i}\\ \displaystyle{\sum_{i=1}^m \alpha_i y_i=0} \end{cases} \end{align} \tag{e.2} $$
将上式的解带入式 $(18)$,即可得到内层问题的解如下,我们令该结果为 $L(\boldsymbol{\alpha})$:
$$ L(\boldsymbol{\alpha})=\min_{\boldsymbol{w},b}L(\boldsymbol{w},b,\boldsymbol{\alpha})=\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_j y_i y_j \boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}_j \tag{e.3} $$
我们发现还有个条件 $\sum_{i=1}^m \alpha_i y_i=0$ 还没用上,它将会在后续作为约束条件使用。
另外,我们令要计算的分割超平面为 $g(\boldsymbol{x})=\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b$,将 $\boldsymbol{w}$ 的值代入后得到:
$$ g(\boldsymbol{x})=\sum_{i=1}^m \alpha_i y_i \boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}+b \tag{e.4} $$
第二步,求解外层问题:
$$ \begin{align} &\max_{\boldsymbol{\alpha}}L(\boldsymbol{\alpha})=\max_{\boldsymbol{\alpha}}\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_j y_i y_j \boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}_j\\ &s.t.\;\sum_{i=1}^m\alpha_i y_i=0,\;\alpha_i\geq0 \end{align} \tag{e.5} $$
我们习惯求最小值,因此给上述问题乘上一个 $-1$ 转换成等价问题:
$$ \begin{align} &\min_{\boldsymbol{\alpha}}L(\boldsymbol{\alpha})=\min_{\boldsymbol{\alpha}}\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_j y_i y_j \boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}_j-\sum_{i=1}^m\alpha_i\\ &s.t.\;\sum_{i=1}^m\alpha_i y_i=0,\;\alpha_i\geq0 \end{align} \tag{e.6} $$
该问题还需要满足 KKT 条件:
$$ \begin{cases} \alpha_i\geq0\\ y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)-1\geq0\\ \alpha_i(y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)-1)=0 \end{cases} \tag{e.7} $$
对于该问题,我们共有 $m$ 个 $\alpha_i$ 等待优化,这个量实在是太大了,不可能同时进行优化求解。使用 SMO 算法可以解决这个问题。
第三步,使用 SMO 求解外层问题:
不妨设我们选择要优化的变量为 $\alpha_1$ 与 $\alpha_2$,问题可以写为:
$$ \begin{align} & \begin{aligned} \min_{\alpha_1,\alpha_2}L(\alpha_1,\alpha_2)&=\min_{\alpha_1,\alpha_2}\frac{1}{2}\alpha_1^2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1+\frac{1}{2}\alpha_2^2\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_2+\alpha_1\alpha_2y_1y_2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2\\ &-\alpha_1-\alpha_2+\alpha_1y_1\sum_{i=3}^m y_i\alpha_i\boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}_1+\alpha_2y_2\sum_{i=3}^m y_i\alpha_i\boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}_2\\ \end{aligned}\\ &s.t.\;\alpha_1y_1+\alpha_2y_2=-\sum_{i=3}^m\alpha_i y_i,\;\alpha_i\geq0 \end{align} \tag{e.8} $$
注意上式的前两项没有 $y_i$ 了,因为 $y_i=\pm1$,所以 $y_i^2=1$ 可以直接省略。另外由于变量相当于只剩 $\alpha_1$ 和 $\alpha_2$,因此后面的双层连加变成了两个单层连加。下面该技巧也会用到多次,也会反向用到。
上式的约束条件可以进行变形:
$$ \begin{align} &\alpha_1y_1+\alpha_2y_2=-\sum_{i=3}^m\alpha_i y_i\\ \Rightarrow&\alpha_1=(-\sum_{i=3}^m\alpha_i y_i-\alpha_2y_2)y_1 \end{align} \tag{e.9} $$
其中除了 $\alpha_1$ 与 $\alpha_2$ 之外的其他变量全部都是已知的,因此 $\alpha_1$ 与 $\alpha_2$ 之间存在确定的关系。如果知道了二者其一,另一个也可以直接计算得到。因此,上面两个变量的优化问题实际上是一个变量的优化问题,完全可以将另一个变量代入替换。
为了式子简洁,我们令:
$$ \begin{align} f&=-\sum_{i=3}^m\alpha_i y_i=\alpha_1y_1+\alpha_2y_2\\ v_i&=\sum_{j=3}^my_j\alpha_j\boldsymbol{x}_j^{\mathrm{T}}\boldsymbol{x}_i=g(x_i)-\sum_{j=1}^2y_j\alpha_j\boldsymbol{x}_j^{\mathrm{T}}\boldsymbol{x}_i-b \end{align} \tag{e.10} $$
通过式 $\text{(e.9)}$ 将式 $\text{(e.8)}$ 中的所有 $\alpha_1$ 替换为 $\alpha_2$,另外使用式 $\text{(e.10)}$ 的第二个等号前半段化简式 $\text{(e.8)}$ 中的表示方法(第二个等号后半段将在后续操作中用到),可以得到:
$$ \begin{align} &\begin{aligned} \min_{\alpha_2}L(\alpha_2)&=\min_{\alpha_2}\frac{1}{2}(f-\alpha_2y_2)^2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1+\frac{1}{2}\alpha_2^2\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_2+(f-\alpha_2y_2)\alpha_2y_2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2\\ &-(f-\alpha_2y_2)y_1-\alpha_2+(f-\alpha_2y_2)v_1+\alpha_2y_2v_2\\ \end{aligned}\\ &s.t.\;\alpha_i\geq0 \end{align} \tag{e.11} $$
此时,整个式子已经只剩 $\alpha_2$ 这一个参数了,我们终于可以对它求偏导并置为 $0$ 得到结果了:
$$ \begin{align} \frac{\partial L(\alpha_2)}{\partial\alpha_2}&=\alpha_2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1-fy_2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1+\alpha_2\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_2-fy_2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2-2\alpha_2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2+y_1y_2-1-y_2v_1+y_2v_2=0\\ &\Rightarrow\alpha_2(\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1+\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_2-2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2)=y_2(f\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1-f\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2-y_1+y_2+v_1-v_2) \end{align} \tag{e.12} $$
此时这个式子已经能用来计算结果了,但是还不够简单,编程实现比较麻烦,我们可以进一步进行化简。
首先注意到式 $(28)$ 的后半段,$f$ 和 $v_i$ 其实可以转化成关于 $\alpha_1,\alpha_2$ 的式子,为了区分新算出来的 $\alpha$,我们将$f$ 和 $v_i$ 里的记作 $\alpha_1^{old},\alpha_2^{old}$.同时,我们令损失值 $E_i$ 为预测值与实际值的差:
$$ E_i=g(x_i)-y_i=\sum_{i=j}^m \alpha_j y_j \boldsymbol{x}_j^{\mathrm{T}}\boldsymbol{x_i}+b-y_i \tag{e.13} $$
将 $\text{(e.10)}$ 的后半段与 $\text{(e.13)}$ 代入 $\text{(e.12)}$,即可得到以下式子:
$$ \begin{align} &\alpha_2^{newunc}(\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1+\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_2-2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2)\\ =\;&y_2(f\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1-f\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2-y_1+y_2+v_1-v_2)\\ =\;&y_2((\alpha_1^{old}y_1+\alpha_2^{old}y_2)\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1-(\alpha_1^{old}y_1+\alpha_2^{old}y_2)\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2-y_1+y_2\\ &+g(x_1)-y_1\alpha_1^{old}\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1-y_2\alpha_2^{old}\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_1-b\\ &-g(x_2)+y_1\alpha_1^{old}\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2+y_2\alpha_2^{old}\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_2+b)\\ =\;&y_2(\alpha_2^{old}y_2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1+\alpha_2^{old}y_2\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_2-2\alpha_2^{old}y_2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2+E_1-E_2)\\ =\;&\alpha_2^{old}\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1+\alpha_2^{old}y\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_2-2\alpha_2^{old}y\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2+y_2(E_1-E_2)\\ =\;&\alpha_2^{old}(\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1+\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_2-2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2)+y_2(E_1-E_2) \end{align} \tag{e.14} $$
令 $\eta=\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_1+\boldsymbol{x}_2^{\mathrm{T}}\boldsymbol{x}_2-2\boldsymbol{x}_1^{\mathrm{T}}\boldsymbol{x}_2$,将上式左右同除以 $\eta$ 得到:
$$ \alpha_2^{newunc}=\alpha_2^{old}+\frac{y_2(E_1-E_2)}{\eta} \tag{e.15} $$
如此,我们将式 $\text{(e.12)}$ 化简得到了非常优美的新式子,编程实现时更加简单。
上面求出来的答案并不是最终答案,我们还需要注意到约束条件 $\alpha_i\geq0$,我们计算得到的 $\alpha_1$ 和 $\alpha_2$ 都要满足该条件。
对 $y_1$ 与 $y_2$ 的符号进行分类讨论:
- $y_1=y_2$
由式 $\text{(e.10)}$,我们不关心符号,因此将符号并入 $t$ 中得到:
$$ \begin{align} &y_1\alpha_1+y_2\alpha_2=f\\ \Rightarrow\;&\alpha_1+\alpha_2=t \end{align} $$
由于 $\alpha_1\geq0,\;\alpha_2\geq0$ 可知:
$$ 0\leq\alpha_2^{new}\leq t=\alpha_1^{old}+\alpha_2^{old} $$
由此,我们可以将 $\alpha_2^{newunc}$ 剪辑:
$$ \alpha_2^{new}= \begin{cases} \alpha_1^{old}+\alpha_2^{old},&\alpha_1^{old}+\alpha_2^{old}<\alpha_2^{newunc}\\ \alpha_2^{newunc},&0\leq\alpha_2^{newunc}\leq\alpha_1^{old}+\alpha_2^{old}\\ 0,&\alpha_2^{newunc}<0 \end{cases} $$
- $y_1\neq y_2$
由式 $\text{(e.10)}$,我们不关心符号,因此将符号并入 $t$ 中得到:
$$ \begin{align} &y_1\alpha_1+y_2\alpha_2=f\\ \Rightarrow\;&\alpha_2-\alpha_1=t \end{align} $$
由于 $\alpha_1\geq0,\;\alpha_2\geq0$ 可知:
$$ 0\leq\alpha_2^{new}\leq t=\alpha_2^{old}-\alpha_1^{old} $$
由此,我们可以将 $\alpha_2^{newunc}$ 剪辑:
$$ \alpha_2^{new}= \begin{cases} \alpha_1^{old}+\alpha_2^{old},&\alpha_2^{old}-\alpha_1^{old}<\alpha_2^{newunc}\\ \alpha_2^{newunc},&0\leq\alpha_2^{newunc}\leq\alpha_2^{old}-\alpha_1^{old}\\ 0,&\alpha_2^{newunc}<0 \end{cases} $$
2.2 软间隔
2.2.1 软间隔的定义
上述硬间隔 SVM 考虑的情况比较理想,样本点不存在噪音。如果样本点存在噪音,将会对硬间隔 SVM 造成干扰,导致泛化能力下降。或者样本点线性不可分,硬间隔 SVM 就无法处理。
在硬间隔 SVM 里,我们要求两类样本点一定分别分布于分割超平面两侧,即样本点一定被分割超平面正确分割。在软间隔 SVM 里,我们降低这个要求,允许样本点被错误分类。
如果样本点能随便被错误分类,那么就没办法找最优解了,因此样本点被错误分类时要有一定的代价,而正确分类时没有代价。我们将其与 $\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b=\pm1$ 距离作为代价(松弛变量)$\xi\geq0$:
$$ \xi_i=l(y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)-1) $$
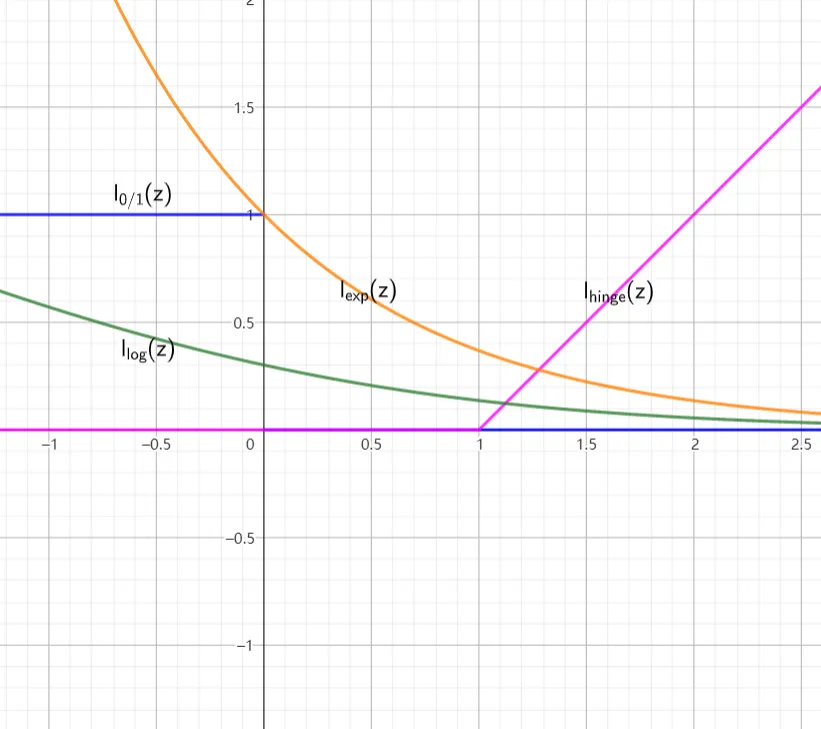
其中,$l(\cdot)$ 可以有多种选择,下面的后三个是连续的函数:
$$ \begin{align} l_{0/1}(z)&= \begin{cases} 1&z<0\\ 0&\text{otherwise} \end{cases}\\\\ l_{\text{hinge}}(z)&=\max\{0,1-z\}\\\\ l_{\text{exp}}&=e^{-z}\\\\ l_{\text{log}}&=\log(1+e^{-z}) \end{align} $$
它们的函数图像如下:
2.2.2 待求解的问题
将硬间隔 SVM 的问题加上松弛变量后,便是软间隔 SVM 待求解的问题:
$$ \begin{align} &\min_{\boldsymbol{w},b}\frac{1}{2}\lVert\boldsymbol{w}\rVert^2+C\sum_{i=1}^m\xi_i\\ &s.t.\;y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)\geq1-\xi_i \end{align} $$
其中 $C$ 的值是松弛量的权重,$C$ 越大即代表优化该问题时,更多考虑松弛量,即让错误分类的样本越少,反之则是允许错误分类的样本越多。
2.2.3 求解支持向量机
软间隔与硬间隔 SVM 的求解过程基本相同,因此下面写的比较简略。
由拉格朗日乘子法,我们列出拉格朗日函数:
$$ L(\boldsymbol{w},b,\boldsymbol{\alpha},\boldsymbol{\xi},\boldsymbol{\mu})=\frac{1}{2}\lVert\boldsymbol{w}\rVert^2+C\sum_{i=1}^m\xi_i+\sum_{i=1}^m \alpha_i(1-y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b))-\sum_{i=1}^m\mu_i\xi_i $$
由于 $\xi_i\geq0$,因此最后一项是减而不是加。
其中 $\alpha_i\geq0,\;\mu_i\geq0$,为两种拉格朗日乘子;$m$ 为样本点的数量。
原问题为:
$$ \min_{\boldsymbol{w},b,\boldsymbol{\xi}}\max_{\boldsymbol{\alpha},\boldsymbol{\mu}}L(\boldsymbol{w},b,\boldsymbol{\alpha},\boldsymbol{\xi},\boldsymbol{\mu}) $$
转化为对偶问题:
$$ \max_{\boldsymbol{\alpha},\boldsymbol{\mu}}\min_{\boldsymbol{w},b,\boldsymbol{\xi}}L(\boldsymbol{w},b,\boldsymbol{\alpha},\boldsymbol{\xi},\boldsymbol{\mu}) $$
对内层问题,求偏导得到解:
$$ \begin{align} &\begin{cases} \displaystyle{\frac{\partial L(\boldsymbol{w},b,\boldsymbol{\alpha},\boldsymbol{\xi},\boldsymbol{\mu})}{\partial\boldsymbol{w}}=\boldsymbol{w}-\sum_{i=1}^m \alpha_i y_i\boldsymbol{x}_i=0}\\ \displaystyle{\frac{\partial L(\boldsymbol{w},b,\boldsymbol{\alpha},\boldsymbol{\xi},\boldsymbol{\mu})}{\partial b}=\sum_{i=1}^m \alpha_i y_i=0}\\ \displaystyle{\frac{\partial L(\boldsymbol{w},b,\boldsymbol{\alpha},\boldsymbol{\xi},\boldsymbol{\mu})}{\partial\xi_i}}=C-\alpha_i-\mu_i=0 \end{cases}\\ \Rightarrow &\begin{cases} \displaystyle{\boldsymbol{w}=\sum_{i=1}^m \alpha_i y_i \boldsymbol{x}_i}\\ \displaystyle{\sum_{i=1}^m \alpha_i y_i=0}\\ \displaystyle{C=\alpha_i+\mu_i} \end{cases} \end{align} $$
由 $\alpha_i\geq0,\;\mu_i\geq0,\;C=\alpha_i+\mu_i$ 可得:$0\leq\alpha_i\leq C$. 回代后,得到再对外层问题求解:
$$ \begin{align} &\max_{\boldsymbol{\alpha}}L(\boldsymbol{\alpha})=\max_{\boldsymbol{\alpha}}\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_j y_i y_j \boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}_j\\ &\begin{aligned} s.t.\;&\sum_{i=1}^m\alpha_i y_i=0,\\ &0\leq\alpha_i\leq C\\ &\alpha_i\geq0\\ \end{aligned} \end{align} $$
该问题还需要满足 KKT 条件:
$$ \begin{cases} \alpha_i\geq0\\ \mu_i\geq0\\ \xi_i\geq0\\ \mu_i\xi_i\geq0\\ y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)-1+\xi_i\geq0\\ \alpha_i(y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)-1+\xi_i)=0 \end{cases} $$
接下来的 SMO 过程一模一样,最后得到:
$$ \alpha_2^{newunc}=\alpha_2^{old}+\frac{y_2(E_1-E_2)}{\eta} $$
然后要对其进行剪辑:
$$ \alpha_2^{new}= \begin{cases} H,&H<\alpha_2^{newunc}\\ \alpha_2^{newunc},&L\leq\alpha_2^{newunc}\leq H\\ L,&\alpha_2^{newunc}<L \end{cases} $$
具体的范围如下,对 $y_1,y_2$ 分类讨论:
- $y_1=y_2$
$$ \begin{cases} L=\max\{0,\alpha_2^{old}-\alpha_1^{old}-C\}\\ H=\min\{C,\alpha_2^{old}-\alpha_1^{old}\} \end{cases} $$
- $y_1\neq y_2$
$$ \begin{cases} L=\max\{0,\alpha_2^{old}-\alpha_1^{old}\}\\ H=\min\{C,C+\alpha_2^{old}-\alpha_1^{old}\} \end{cases} $$
3. 非线性 SVM
$\varphi$ 是一个从低维的输入空间 $\mathcal{X}$ 到高维的希尔伯特空间 $\mathcal{H}$ 的映射。如果存在函数 $\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)$ 对于任意 $\boldsymbol{x}_i,\boldsymbol{x}_j\in\mathcal{X}$ 都有:
$$ \kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)=\varphi(\boldsymbol{x_i})\varphi(\boldsymbol{x_j}) $$
就称 $\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)$ 为核函数。
通过核函数,我们可以将样本点从低维空间 $\mathcal{X}$ 映射到高维 $\mathcal{H}$,在低维空间中线性不可分的样本点,可能在高维空间中线性可分,由此便可以解决线性不可分的数据。
对于核函数 $\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)$,我们没有必要知道其对应的 $\varphi(\boldsymbol{x})$ 是多少,因为它的表达可能会非常复杂。我们只需要知道 $\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)$ 的表达式便可以使用它了。常用的核函数有:
| 名称 | 表达式 |
|---|---|
| 线性核 | $\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)=\boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}_j$ |
| 多项式核 | $\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)=(\boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}_j)^d,\;d\geq1$ |
| 高斯核 | $\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)=\exp(-\frac{\lVert\boldsymbol{x}_i-\boldsymbol{x}_j\rVert^2}{2\sigma^2}),\;\sigma>0$ |
| 拉普拉斯核 | $\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)=\exp(-\frac{\lVert\boldsymbol{x}_i-\boldsymbol{x}_j\rVert}{2\sigma^2}),\;\sigma>0$ |
| Sigmoid 核 | $\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)=\tanh(\beta\boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}_j+\theta),\;\beta>0,\;\theta<0$ |
要使用核函数,公式推导过程和前文一模一样,只需要把公式内的 $\boldsymbol{x}_i^{\mathrm{T}}\boldsymbol{x}_j$ 替换成 $\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)$ 就行了。
本文采用 CC BY-SA 4.0 许可,本文 Markdown 源码:Haotian-BiJi
吆西