数据结构 | 可持久化线段树以及主席树
可持久化数据结构:总是可以保留每一个历史版本的数据结构。
可持久化线段树:可以保存每一次操作的历史版本的线段树。
可持久化权值线段树 (主席树):可以保存每一次操作的历史版本的权值线段树。
前置内容:线段树 https://io.zouht.com/117.html
1 可持久化线段树
1.1 问题引入
我们都知道线段树可以维护序列的区间信息,支持区间修改、区间查询,但我们现在要求保留历史版本。
对于一个序列 $a_1,a_2,\dots,a_n$,给出操作版本号 $x$ 和区间 $[l,r]$,可以进行修改和查询操作:
- 对于第 $x$ 个版本,修改 $a_l,a_{l+1},\dots,a_r$ 的值,作为一个新版本。
- 对于第 $x$ 个版本,查询 $a_l,a_{l+1},\dots,a_r$ 的和。
1.1 原理
既然持久化的目标是保留每一个历史版本,那最朴素的思想就是每次操作都开一棵新的线段树。但是不用算都知道,这样操作的话空间复杂度绝对是不可接受的。
我们先观察一下线段树的一次操作造成的影响,以下图这棵树为例,节点上的数字代表 ID,节点具体维护的值我们暂不考虑:
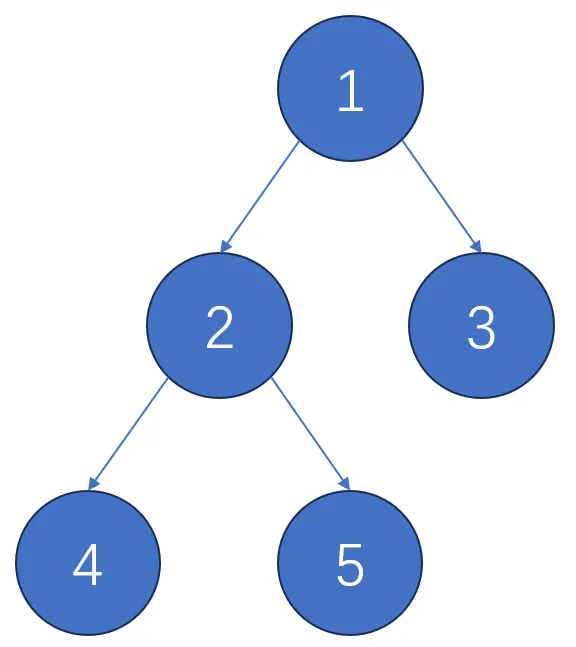
如果我们要对 $5$ 号节点进行更新,那么根据线段树的性质,会影响的节点仅仅是 $1,2,5$,其他节点的值不会被影响:
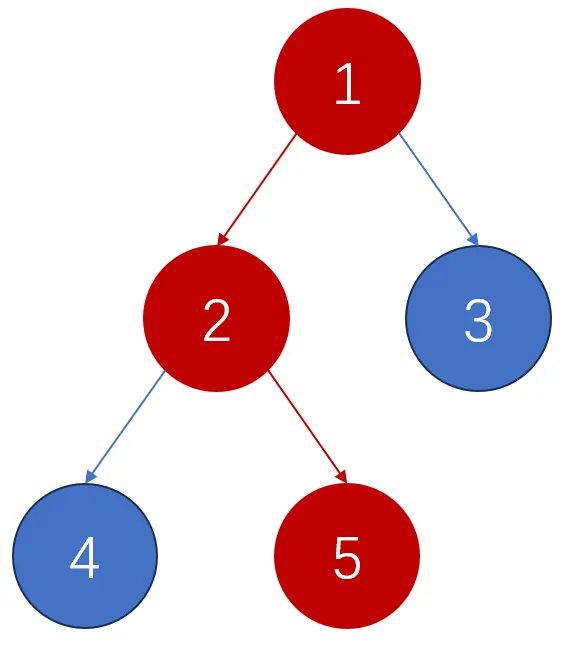
推广来说,对一个节点进行修改,会影响的节点仅仅是从根节点到该节点的一条链,也就是会影响 $\log_2 n$ 个节点。我们最开始的朴素思想是把整个线段树复制一遍存下来,这就会导致很多空间被浪费,因为除了那条链上的节点,其他节点其实是完全没变的。
那么,我们就需要找到一个策略来节省空间,仅保存被更新的节点。
这个策略便是我们不实际修改线段树的节点,所有更新都以额外加点的形式来实现。
如果一次修改造成了一条链的更新,那么我们就额外新增这条链修改后的节点,对于没变的节点,指针直接指向原版本的节点即可。通俗来说,就是我们的更新就像打补丁一样,旧的仍然在哪里,被修改的内容就是那个补丁。
需要注意的是,这样做的话就不能用堆式存储法(对于节点 $x$,左儿子为 $2x$,右儿子为 $2x+1$),我们得动态开点,并保存左右儿子的编号,相当于左儿子指针和右儿子指针。
另外,每次更新会产生一个新的根节点,我们需要一个 root 数组来保存每个版本的根节点编号。
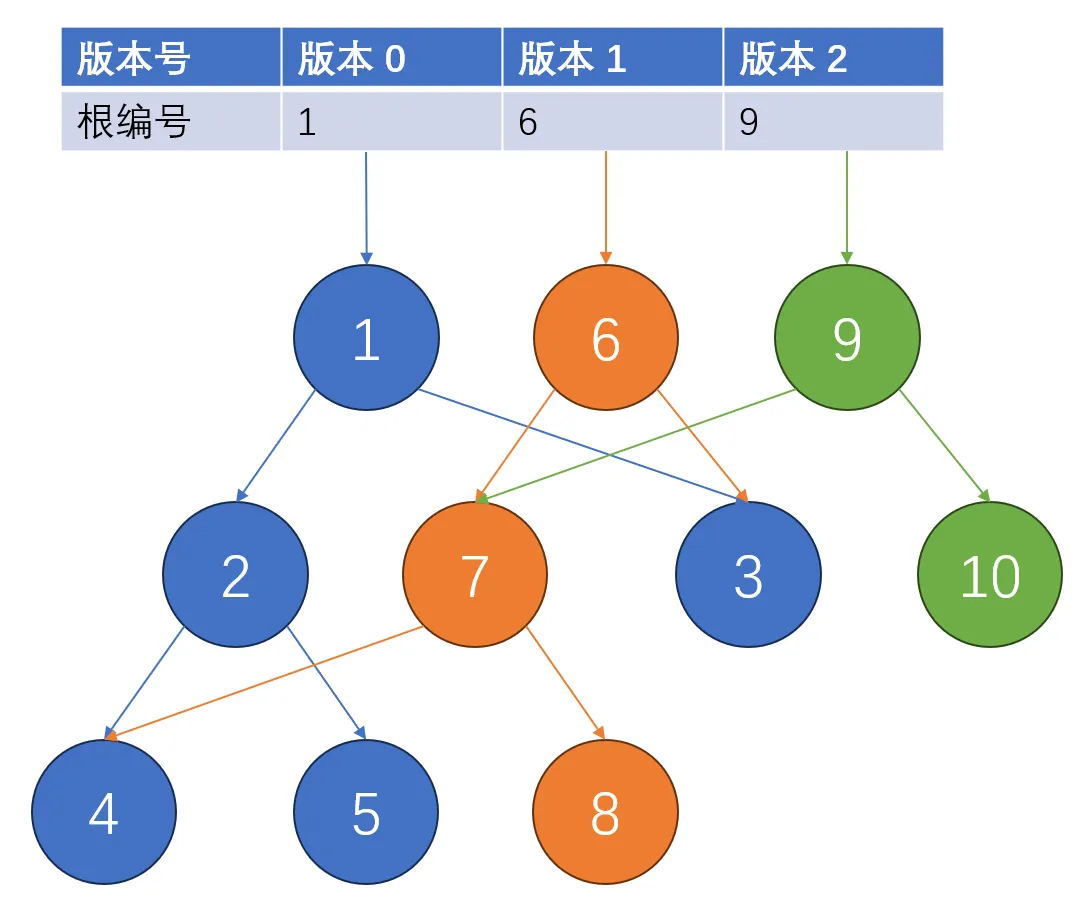
例如,对于上文的示例,我们进行连续的两个操作:
- 版本 $0$ $\to$ 修改节点 $5$ 的值 $\to$ 版本 $1$
- 版本 $1$ $\to$ 修改节点 $3$ 的值 $\to$ 版本 $2$
那么,可持久化线段树形成的结构将会是下图:
1.2 实现
原理了解了,接下来的问题就是如何用代码实现了。
首先需要注意的是节点空间要多开点,一般可以开题目规模的 $32$ 倍(MAXN << 5)。因为每次修改将会产生 $\log n$ 个新点,如果进行 $q$ 次修改操作,最坏情况下需要的空间约为 $2n+q\log n$. 如果 $n,q$ 均为 $10^6$,则需要的空间约为 $21$ 倍的 $n$.
其次就是不能用堆式存储法直接计算编号,而是需要用 $lson,rson$ 两个数组储存左右节点的编号。对于节点 $i$,它的左儿子为 $lson_i$,右儿子为 $rson_i$.
具体实现就直接参考下文代码即可,如果学习过线段树应该比较好理解,因为其实核心思想是一样的,可持久化只是额外的功能。
该模板仅支持单点修改,下面我们将会讲解区间修改。
对应题目:https://www.luogu.com.cn/problem/P3919
namespace pst
{
/* ### array index must start from ONE ### */
constexpr int MAXN = 1e6;
int n;
int root[MAXN];
int val[(MAXN << 5) + 10], lson[(MAXN << 5) + 10], rson[(MAXN << 5) + 10], cur_idx = 0;
int build(const vector<int> &arr, int s, int t)
{
int now = ++cur_idx;
if (s == t)
{
val[now] = arr[s];
return now;
}
int m = (s + t) / 2;
lson[now] = build(arr, s, m);
rson[now] = build(arr, m + 1, t);
return now;
}
int clone_node(int orig)
{
++cur_idx;
val[cur_idx] = val[orig];
lson[cur_idx] = lson[orig];
rson[cur_idx] = rson[orig];
return cur_idx;
}
int update(int x, int c, int s, int t, int p)
{
int now = clone_node(p);
if (s == t)
{
val[now] = c;
return now;
}
int m = (s + t) / 2;
if (x <= m)
lson[now] = update(x, c, s, m, lson[now]);
else
rson[now] = update(x, c, m + 1, t, rson[now]);
return now;
}
int query(int x, int s, int t, int p)
{
if (s == t)
return val[p];
int m = (s + t) / 2;
if (x <= m)
return query(x, s, m, lson[p]);
else
return query(x, m + 1, t, rson[p]);
}
};1.3 区间修改与标记永久化
对于普通线段树,我们采用的区间修改策略是懒惰标记法,需要把标记上下传也就是 push_down 和 push_up. 但在可持久化线段树中,如果也这么做那将会导致严重的问题。
考虑上面的例子:
如果我们有一个标记在 $9$ 节点,如果对标记进行 push_down 下传,可以发现它会被传到 $7$ 节点,甚至再往下会传到 $4$ 节点,那这样的话对版本 $2$ 的修改就把版本 $1$ 和 $0$ 全破坏了。要避免这个问题只能把受影响节点全部新建,会浪费许多空间。
因此,使用懒惰标记上下传的方式无法解决这个问题,我们用懒惰标记永久化来解决。
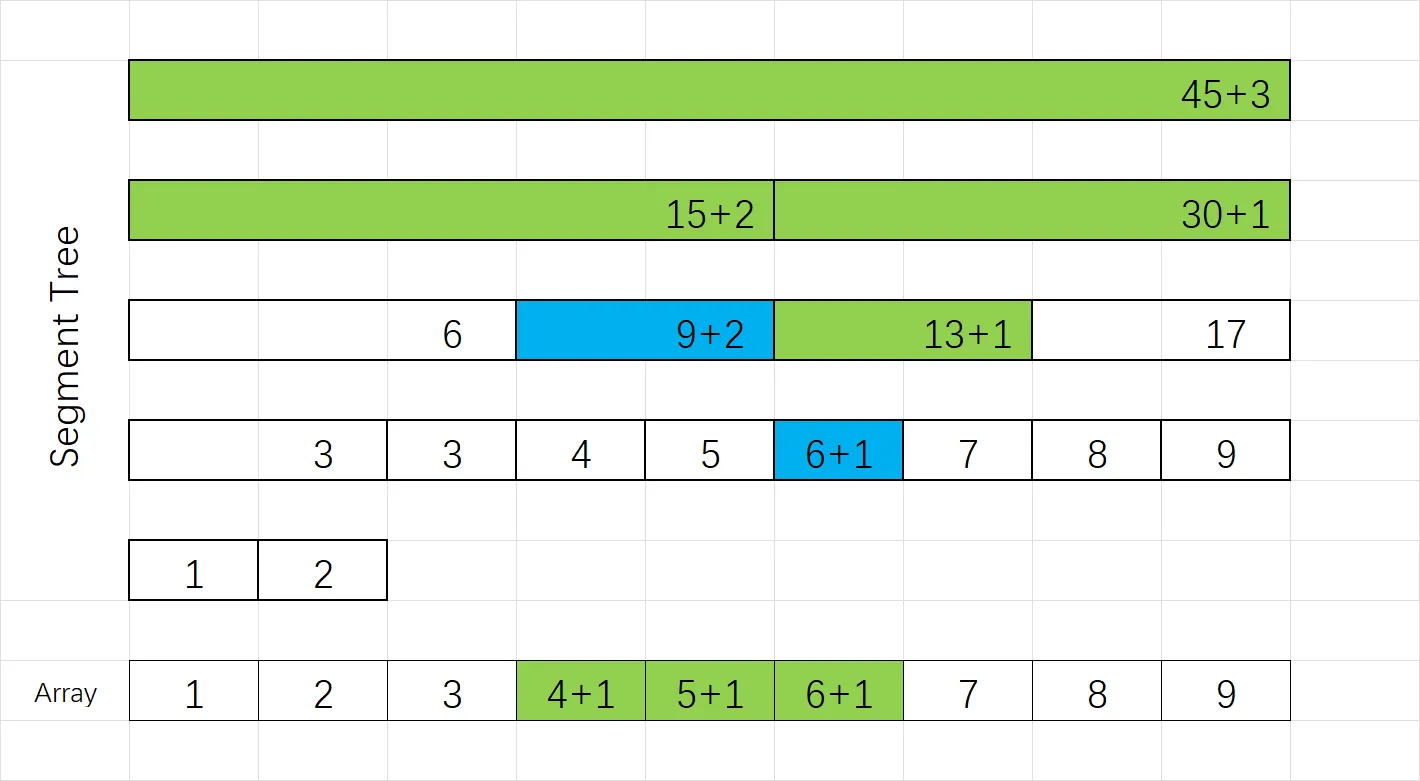
例如上面这个线段树,储存了 $9$ 个元素 $1,2,\dots,9$,我们对 $[4,6]$ 这个区间的元素统一 $+1$,其中绿色和蓝色代表会更新的节点,也就是新版本会额外创建的新节点。
对于这些节点,我们会将它实际更新,更新方式就是计算区间交叉长度来获取增长值。其中,蓝色的节点比较特殊,它们会被标上懒惰标记。这些步骤和标记上下传是一致的。
不一样的地方就是,节点拿到标记后不再下传。也就是即使之后询问到了标蓝的节点,它们也不会将标记 push_down 下去。那该怎么计算询问结果呢?答案是在 query 函数里传入节点的标记值。
例如更新后,我们对 $[3,4]$ 这个区间进行询问,对于 $4$ 号位置的节点,它实际上是被上一次 $+1$ 了,但是懒惰标记在它的上一层且不会传给它。此时如果请求来到拿着懒惰标记的节点,它就会将标记值传入向下一层的 query 函数,相当于告诉下一层它身上现在有多少个懒惰标记,但是不真正把标记传给它。
下一层的节点受到 query 请求后,就会计算得到结果,同时将会把传给它的标记值根据区间长度加入结果再返回给上层,完成计算。
文字表述比较抽象,建议对照代码:
namespace pst
{
/* ### array index must start from ONE ### */
constexpr int MAXN = 1e6;
int n;
signed root[MAXN];
int cur_idx = 0;
int val[(MAXN << 5) + 10], mark[(MAXN << 5) + 10];
signed lson[(MAXN << 5) + 10], rson[(MAXN << 5) + 10];
int build(const vector<int> &arr, int s, int t)
{
int now = ++cur_idx;
if (s == t)
{
val[now] = arr[s];
return now;
}
int m = (s + t) / 2;
lson[now] = build(arr, s, m);
rson[now] = build(arr, m + 1, t);
val[now] = val[lson[now]] + val[rson[now]];
return now;
}
int clone_node(int orig)
{
++cur_idx;
val[cur_idx] = val[orig];
mark[cur_idx] = mark[orig];
lson[cur_idx] = lson[orig];
rson[cur_idx] = rson[orig];
return cur_idx;
}
int update(int l, int r, int c, int s, int t, int p)
{
int now = clone_node(p);
val[now] += (min(r, t) - max(l, s) + 1) * c;
if (l <= s && t <= r)
{
mark[now] += c;
return now;
}
int m = (s + t) / 2;
if (l <= m)
lson[now] = update(l, r, c, s, m, lson[now]);
if (r > m)
rson[now] = update(l, r, c, m + 1, t, rson[now]);
return now;
}
int query(int l, int r, int s, int t, int p, int mk = 0)
{
if (l <= s && t <= r)
return val[p] + mk * (t - s + 1);
int m = (s + t) / 2, ans = 0;
if (l <= m)
ans += query(l, r, s, m, lson[p], mk + mark[p]);
if (r > m)
ans += query(l, r, m + 1, t, rson[p], mk + mark[p]);
return ans;
}
};模板题:https://acm.hdu.edu.cn/showproblem.php?pid=4348
该题数据较大需要开 long long,同时该题内存限制比较极限(64MB),需要注意节省内存。
2 可持久化权值线段树(主席树)
2.1 普通线段树和权值线段树
首先,对权值线段树这个术语做一下解释。
对于普通线段树,我们都知道维护的是数组区间信息,例如区间和、区间最大 / 小值,维护的内容是数据本身。
而对于权值线段树,维护的是数组区间内数的个数信息,例如 $1$ 的个数、$2$ 的个数,维护的内容相当于许多桶。
因此,对比总结一下:
- 普通线段树:维护信息,按个数开空间,维护具体信息。
- 权值线段树:维护桶,按值域(可离散化处理),维护个数。
2.2 问题引入
给定 $n$ 个整数构成的序列 $a$,将对于指定的闭区间 $[l,r]$ 查询其区间内的第 $k$ 小值。
该问题应该是主席树最经典的应用了。
2.3 原理
对于一个权值线段树,储存的是 $1,2,\dots,n$ 的个数。每个节点储存的都是一个值域内数的个数,对于一个节点,如果它维护的值域范围是 $[low,high]$,令中点为 $mid=(low+high)/2$,那么它的左儿子维护的范围为 $[low,mid]$,右儿子维护的范围为 $(mid,high]$.
我们先不想具体实现,假设我们已经有了一个可持久化权值线段树,如何解决区间第 $k$ 小问题。可以按照以下方式完成:
对于一个序列 $a_1,a_2,\dots,a_n$,我们可以按从左到右的顺序,依次将其加入可持久化权值线段树。那么区间 $[l,r]$ 的数插入时,对应的历史版本便是版本 $l$ 到版本 $r$.
如果我们要查询区间 $[l,r]$ 内第 $k$ 大的数,那么我们从根节点开始,根节点代表处于整个值域 $[low,high]$ 的数的个数。
- 先找根节点的左儿子的 $r$ 版本的值,即代表 $r$ 版本时处于 $[low,mid]$ 的数的个数,记为 $sum_r$.
- 再找根节点的左儿子的 $l - 1$ 版本的值,即代表 $l-1$ 版本时处于 $[low,mid]$ 的数的个数,记为 $sum_{l-1}$.
那么 $sum_r-sum_{l-1}$ 的意义便是,区间 $[l,r]$ 内大小处于 $[low,mid]$ 的数的个数,记为 $x$.
- 如果 $x\geq k$,说明 $[low,mid]$ 范围包含的范围比我们要找的范围要大,因此我们递归进入左子节点更细致地查找。
- 如果 $x<k$,说明 $[low,mid]$ 范围包含了 $[l,r]$ 内前 $x$ 小的数,我们要找的是前 $k$ 小的数,那么我们应该再递归进入右子节点找前 $k-x$ 小的数,就相当于原区间的第 $k$ 小的数。
按上面这种方案递归下去,最终一定会到 $low=high$ 的状态,这个状态便是找到答案,第 $k$ 小的数就是 $low$,递归终止。
2.4 实现
可持久化权值线段树的实现与可持久化线段树几乎一致,唯一区别就是建树方式和更新方式。
建树时不传入初始数组,值全部初始化为 $0$,另外线段树大小不是数组长度,而是值域大小。
更新代表的是加入数 $x$,需要将所有值域包含它的节点 $+1$.
还有至关重要的一点便是离散化,int 的值域在 $10^9$ 等级,如果我们要开一个大小为 $10^9$ 的可持久化权值线段树,那空间也是要爆的。但是考虑到一般题目的数的个数都较少,在 $10^6$ 左右,那么我们可以用离散化,仅储存出现过的数,不考虑没出现过的数。离散化的方式可以对原数据排序、去重后二分完成,具体可以参考代码实现。
namespace hjt
{
/* ### array index must start from ONE ### */
constexpr int MAXN = 1e6;
int n;
int sum[(MAXN << 5) + 10], lson[(MAXN << 5) + 10], rson[(MAXN << 5) + 10], cur_idx = 0;
int root[MAXN], cur_ver = 0;
int build(int s, int t)
{
int now = ++cur_idx;
if (s == t)
{
sum[now] = 0;
return now;
}
int m = (s + t) / 2;
lson[now] = build(s, m);
rson[now] = build(m + 1, t);
return now;
}
int clone_node(int orig)
{
++cur_idx;
sum[cur_idx] = sum[orig] + 1;
lson[cur_idx] = lson[orig];
rson[cur_idx] = rson[orig];
return cur_idx;
}
int update(int x, int s, int t, int p)
{
int now = clone_node(p);
if (s == t)
return now;
int m = (s + t) / 2;
if (x <= m)
lson[now] = update(x, s, m, lson[now]);
else
rson[now] = update(x, m + 1, t, rson[now]);
return now;
}
int query(int x, int l, int r, int s, int t)
{
if (s == t)
return s;
int delt = sum[lson[r]] - sum[lson[l]];
int m = (s + t) / 2;
if (x <= delt)
return query(x, lson[l], lson[r], s, m);
else
return query(x - delt, rson[l], rson[r], m + 1, t);
}
};solve() 函数也附上,防止不知道怎么用,对应的是模板题:https://www.luogu.com.cn/problem/P3834
void solve()
{
int n, m;
cin >> n >> m;
vector<int> a(n + 10);
for (int i = 1; i <= n; i++)
cin >> a[i];
auto b = a;
sort(b.begin() + 1, b.begin() + 1 + n);
int uni = unique(b.begin() + 1, b.begin() + 1 + n) - b.begin() - 1;
hjt::root[0] = hjt::build(1, uni);
for (int i = 1; i <= n; i++)
{
int t = lower_bound(b.begin() + 1, b.begin() + 1 + uni, a[i]) - b.begin();
hjt::root[i] = hjt::update(t, 1, m, hjt::root[i - 1]);
}
for (int i = 1; i <= m; i++)
{
int l, r, k;
cin >> l >> r >> k;
int t = hjt::query(k, hjt::root[l - 1], hjt::root[r], 1, m);
cout << b[t] << endl;
}
}本文采用 CC BY-SA 4.0 许可,本文 Markdown 源码:Haotian-BiJi